
示例视频由 ModelScope 生成。
最近生成模型方向的进展如排山倒海,令人目不暇接,而文生视频将是这一连串进展的下一波。尽管大家很容易从字面上理解文生视频的意思,但它其实是一项相当新的计算机视觉任务,其要求是根据文本描述生成一系列时间和空间上都一致的图像。虽然看上去这项任务与文生图极其相似,但众所周知,它的难度要大得多。这些模型是如何工作的,它们与文生图模型有何不同,我们对其性能又有何期待?
在本文中,我们将讨论文生视频模型的过去、现在和未来。我们将从回顾文生视频和文生图任务之间的差异开始,并讨论无条件视频生成和文生视频两个任务各自的挑战。此外,我们将介绍文生视频模型的最新发展,探索这些方法的工作原理及其性能。最后,我们将讨论我们在 Hugging Face 所做的工作,这些工作的目标就是促进这些模型的集成和使用,我们还会分享一些在 Hugging Face Hub 上以及其他一些地方的很酷的演示应用及资源。

根据各种文本描述输入生成的视频示例,图片来自论文 Make-a-Video。
文生视频与文生图
最近文生图领域的进展多如牛毛,大家可能很难跟上最新的进展。因此,我们先快速回顾一下。
就在两年前,第一个支持开放词汇 (open-vocabulary) 的高质量文生图模型出现了。第一波文生图模型,包括 VQGAN-CLIP、XMC-GAN 和 GauGAN2,都采用了 GAN 架构。紧随其后的是 OpenAI 在 2021 年初发布的广受欢迎的基于 transformer 的 DALL-E、2022 年 4 月的 DALL-E 2,以及由 Stable Diffusion 和 Imagen 开创的新一波扩散模型。Stable Diffusion 的巨大成功催生了许多产品化的扩散模型,例如 DreamStudio 和 RunwayML GEN-1; 同时也催生了一批集成了扩散模型的产品,例如 Midjourney。
尽管扩散模型在文生图方面的能力令人印象深刻,但相同的故事并没有扩展到文生视频,不管是扩散文生视频模型还是非扩散文生视频模型的生成能力仍然非常受限。文生视频模型通常在非常短的视频片段上进行训练,这意味着它们需要使用计算量大且速度慢的滑动窗口方法来生成长视频。因此,众所周知,训得的模型难以部署和扩展,并且在保证上下文一致性和视频长度方面很受限。
文生视频的任务面临着多方面的独特挑战。主要有:
- 计算挑战: 确保帧间空间和时间一致性会产生长期依赖性,从而带来高计算成本,使得大多数研究人员无法负担训练此类模型的费用。
- 缺乏高质量的数据集: 用于文生视频的多模态数据集很少,而且通常数据集的标注很少,这使得学习复杂的运动语义很困难。
- 视频字幕的模糊性: “如何描述视频从而让模型的学习更容易”这一问题至今悬而未决。为了完整描述视频,仅一个简短的文本提示肯定是不够的。一系列的提示或一个随时间推移的故事才能用于生成视频。
在下一节中,我们将分别讨论文生视频领域的发展时间线以及为应对这些挑战而提出的各种方法。概括来讲,文生视频的工作主要可以分为以下 3 类:
- 提出新的、更高质量的数据集,使得训练更容易。
- 在没有
文本 - 视频对的情况下训练模型的方法。 - 计算效率更高的生成更长和更高分辨率视频的方法。
如何实现文生视频?
让我们来看看文生视频的工作原理以及该领域的最新进展。我们将沿着与文生图类似的研究路径,探索文生视频模型的流变,并探讨迄今为止我们是如何解决文生视频领域的具体挑战的。
与文生图任务一样,文生视频也是个年轻的方向,最早只能追溯到几年前。早期研究主要使用基于 GAN 和 VAE 的方法在给定文本描述的情况下自回归地生成视频帧 (参见 Text2Filter 及 TGANs-C)。虽然这些工作为文生视频这一新计算机视觉任务奠定了基础,但它们的应用范围有限,仅限于低分辨率、短距以及视频中目标的运动比较单一、孤立的情况。

最初的文生视频模型在分辨率、上下文和长度方面极为有限,图像取自 TGANs-C。
受文本 (GPT-3) 和图像 (DALL-E) 中大规模预训练 Transformer 模型的成功启发,文生视频研究的第二波浪潮采用了 Transformer 架构。Phenaki、Make-A-Vide、NUWA、VideoGPT 和 CogVideo 都提出了基于 transformer 的框架,而 TATS 提出了一种混合方法,从而将用于生成图像的 VQGAN 和用于顺序地生成帧的时间敏感 transformer 模块结合起来。在第二波浪潮的诸多框架中,Phenaki 尤其有意思,因为它能够根据一系列提示 (即一个故事情节) 生成任意长视频。同样,NUWA-Infinity 提出了一种双重自回归 (autoregressive over autoregressive) 生成机制,可以基于文本输入合成无限长度的图像和视频,从而使得生成高清的长视频成为可能。但是,Phenaki 或 NUWA 模型均无法从公开渠道获取。
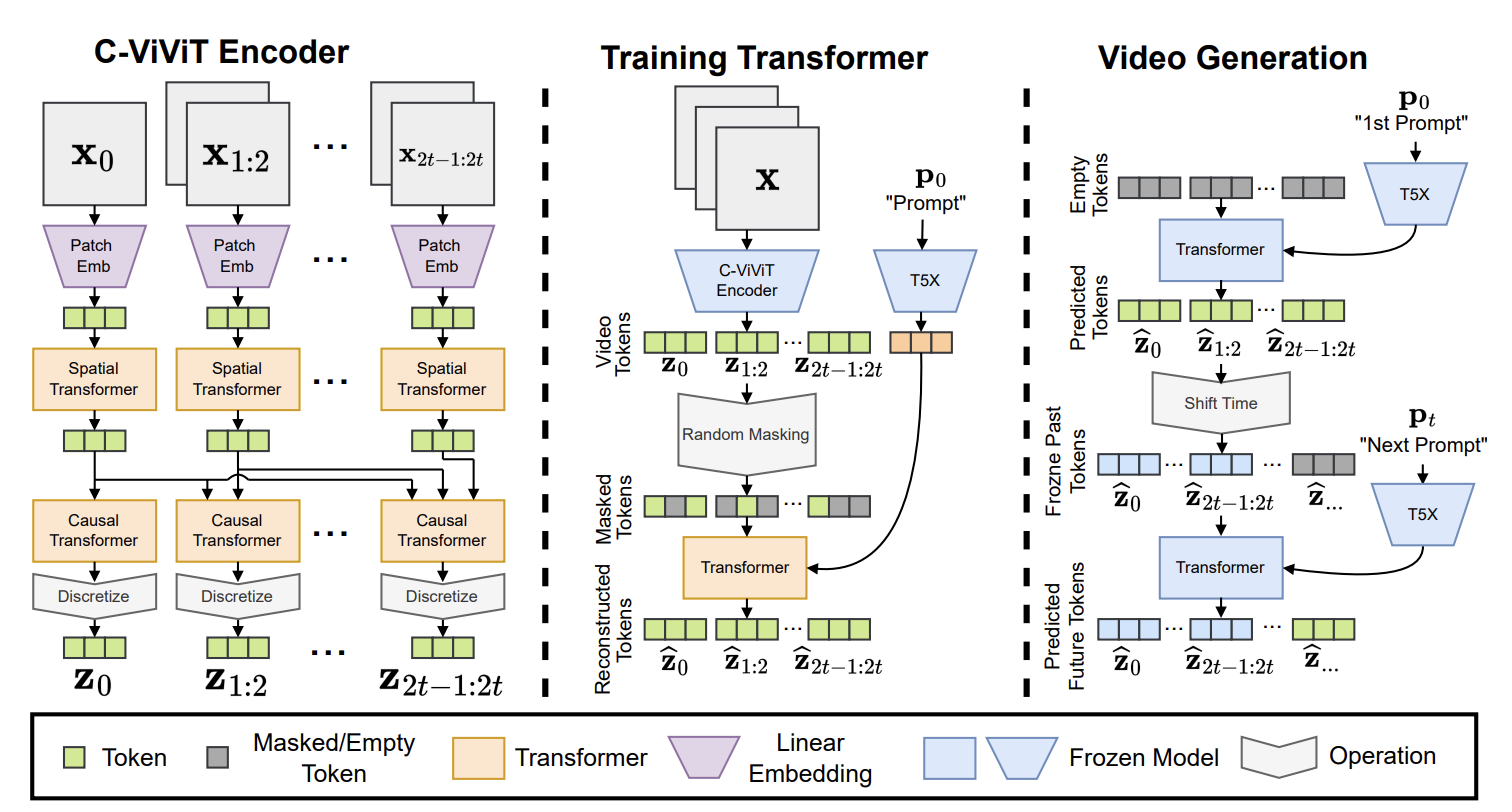
Phenaki 的模型架构基于 transformer,图片来自 此处。
第三波也就是当前这一波文生视频模型浪潮主要以基于扩散的架构为特征。扩散模型在生成多样化、超现实和上下文丰富的图像方面取得了显著成功,这引起了人们对将扩散模型推广到其他领域 (如音频、3D ,最近又拓展到了视频) 的兴趣。这一波模型是由 Video Diffusion Models (VDM) 开创的,它首次将扩散模型推广至视频领域。然后是 MagicVideo 提出了一个在低维隐空间中生成视频剪辑的框架,据其报告,新框架与 VDM 相比在效率上有巨大的提升。另一个值得一提的是 Tune-a-Video,它使用 单文本 - 视频对微调预训练的文生图模型,并允许在保留运动的同时改变视频内容。随后涌现出了越来越多的文生视频扩散模型,包括 Video LDM、Text2Video-Zero、Runway Gen1、Runway Gen2 以及 NUWA-XL。
Text2Video-Zero 是一个文本引导的视频生成和处理框架,其工作方式类似于 ControlNet。它可以基于输入的 文本数据 或 文本 + 姿势混合数据 或 文本 + 边缘混合数据 直接生成 (或编辑) 视频。顾名思义,Text2Video-Zero 是一种零样本模型,它将可训练的运动动力学模块与预训练的文生图稳定扩散模型相结合,而无需使用任何 文本 - 视频对 数据。与 Text2Video-Zero 类似,Runway Gen-1 和 Runway Gen-2 模型可以合成由文本或图像描述的内容引导的视频。这些工作大多数都是在短视频片段上训练的,并且依靠带有滑动窗口的自回归机制来生成更长的视频,这不可避免地导致了上下文差异 (context gap)。 NUWA-XL 解决了这个问题,并提出了一种“双重扩散 (diffusion over diffusion)”方法,并在 3376 帧视频数据上训练模型。最后,还有一些尚未在同行评审的会议或期刊上发表的开源文本到视频模型和框架,例如阿里巴巴达摩院视觉智能实验室的 ModelScope 和 Tencel 的 VideoCrafter。
数据集
与其他视觉语言模型一样,文生视频模型通常在大型 文本 - 视频对 数据集上进行训练。这些数据集中的视频通常被分成短的、固定长度的块,并且通常仅限于少数几个目标的孤立动作。出现这种情况的一部分原因是计算限制,另一部分原因是以有意义的方式描述视频内容这件事本身就很难。而我们看到多模态视频文本数据集和文生视频模型的发展往往是交织在一起的,因此有不少工作侧重于开发更易于训练的更好、更通用的数据集。同时也有一些工作另辟蹊径,对替代解决方案进行了探索,例如 Phenaki 将 文本 - 图像对 与 文本 - 视频对 相结合用于文生视频任务; Make-a-Video 则更进一步,提议仅使用 文本 - 图像对 来学习世界表象信息,并使用单模态视频数据以无监督的方式学习时空依赖性。
这些大型数据集面临与文本图像数据集类似的问题。最常用的文本 - 视频数据集 WebVid 由 1070 万个 文本 - 视频对 (视频时长 5.2 万小时) 组成,并包含一定量的噪声样本,这些样本中的视频文本描述与视频内容是非相干的。其他数据集试图通过聚焦特定任务或领域来解决这个问题。例如,Howto100M 数据集包含 13600 万个视频剪辑,其中文本部分描述了如何一步一步地执行复杂的任务,例如烹饪、手工制作、园艺、和健身。而 QuerYD 数据集则聚焦于事件定位任务,视频的字幕详细描述了目标和动作的相对位置。CelebV-Text 是一个包含超过 7 万个视频的大规模人脸文本 - 视频数据集,用于生成具有逼真的人脸、情绪和手势的视频。
Hugging Face 上的文生视频
使用 Hugging Face Diffusers,你可以轻松下载、运行和微调各种预训练的文生视频模型,包括 Text2Video-Zero 和 阿里巴巴达摩院 的 ModelScope。我们目前正在努力将更多优秀的工作集成到 Diffusers 和 ![]() Transformers 中。
Transformers 中。
Hugging Face 应用演示
在 Hugging Face,我们的目标是使 Hugging Face 库更易于使用并包含最先进的研究。你可以前往 Hub 查看和体验由 ![]() 团队、无数社区贡献者和研究者贡献的 Spaces 演示。目前,上面有 VideoGPT、CogVideo、ModelScope 文生视频 以及 Text2Video-Zero 的应用演示,后面还会越来越多,敬请期待。要了解这些模型能用来做什么,我们可以看一下 Text2Video-Zero 的应用演示。该演示不仅展示了文生视频应用,而且还包含多种其他生成模式,如文本引导的视频编辑,以及基于姿势、深度、边缘输入结合文本提示进行联合条件下的视频生成。
团队、无数社区贡献者和研究者贡献的 Spaces 演示。目前,上面有 VideoGPT、CogVideo、ModelScope 文生视频 以及 Text2Video-Zero 的应用演示,后面还会越来越多,敬请期待。要了解这些模型能用来做什么,我们可以看一下 Text2Video-Zero 的应用演示。该演示不仅展示了文生视频应用,而且还包含多种其他生成模式,如文本引导的视频编辑,以及基于姿势、深度、边缘输入结合文本提示进行联合条件下的视频生成。
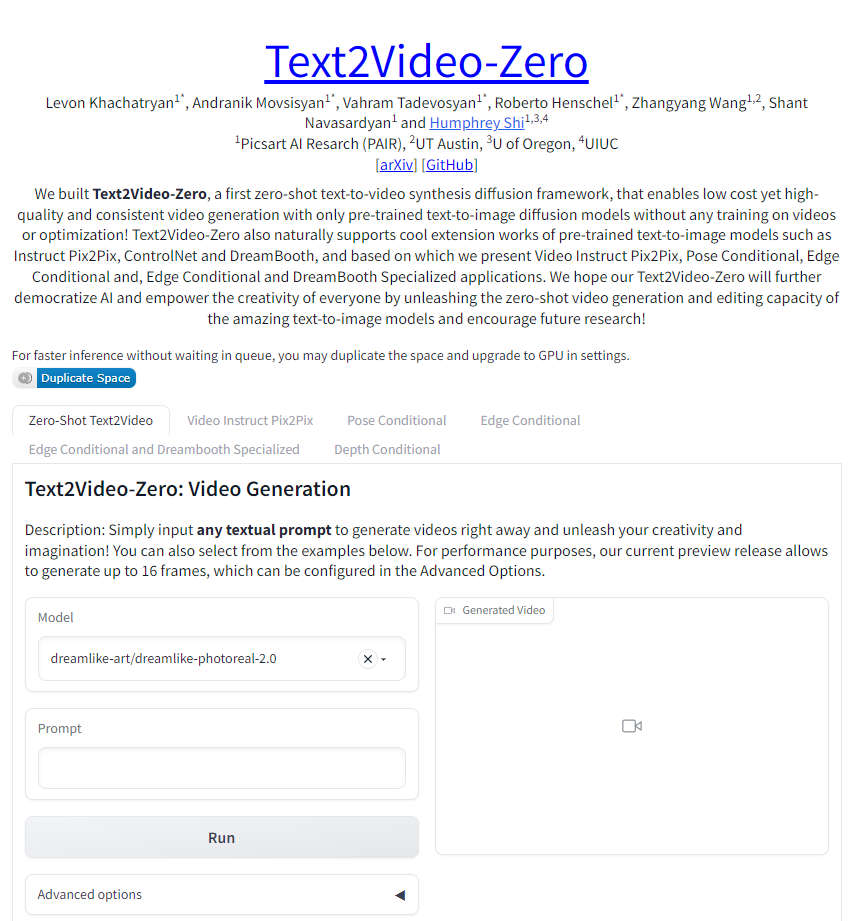
除了使用应用演示来尝试预训练文生视频模型外,你还可以使用 Tune-a-Video 训练演示 使用你自己的 文本 - 视频对微调现有的文生图模型。仅需上传视频并输入描述该视频的文本提示即就可以了。你可以将训得的模型上传到公开的 Tune-a-Video 社区的 Hub 或你私人用户名下的 Hub。训练完成后,只需转到演示的 Run 选项卡即可根据任何文本提示生成视频。
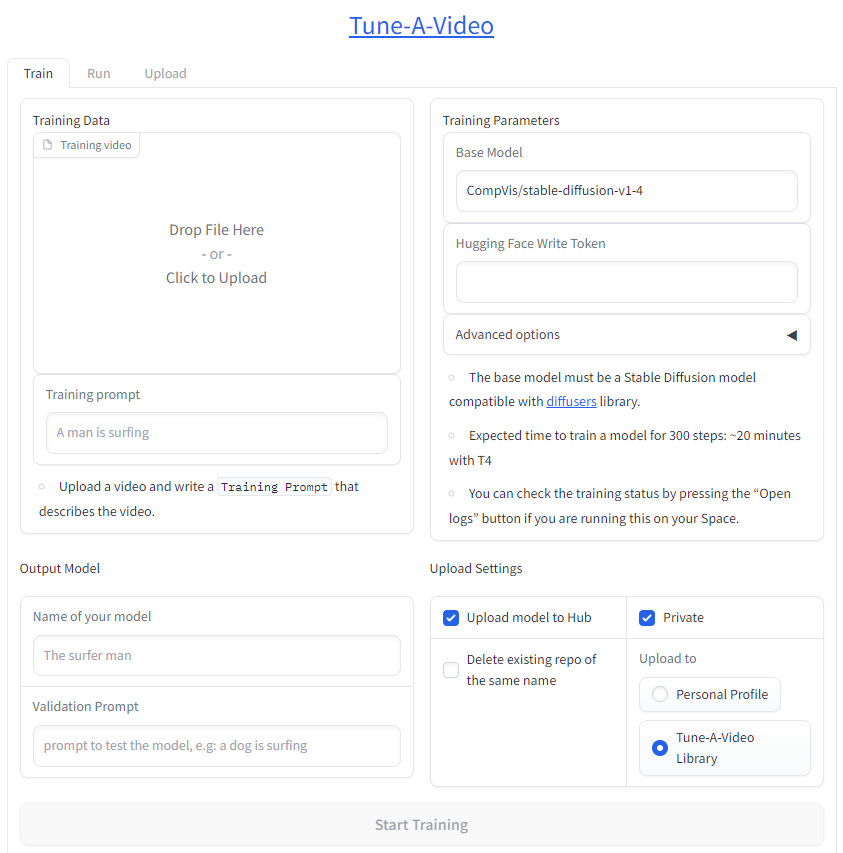
![]() Hub 上的所有 Space 其实都是 Git 存储库,你可以在本地或部署环境中克隆和运行它们。下面克隆一下 ModelScope 演示,安装环境,并在本地运行它。
Hub 上的所有 Space 其实都是 Git 存储库,你可以在本地或部署环境中克隆和运行它们。下面克隆一下 ModelScope 演示,安装环境,并在本地运行它。
git clone https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis
cd modelscope-text-to-video-synthesis
pip install -r requirements.txt
python app.py
这就好了! Modelscope 演示现在已经在你的本地计算机上运行起来了。请注意,Diffusers 支持 ModelScope 文生视频模型,你只需几行代码即可直接加载并使用该模型生成新视频。
import torch
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
from diffusers.utils import export_to_video
pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16")
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
prompt = "Spiderman is surfing"
video_frames = pipe(prompt, num_inference_steps=25).frames
video_path = export_to_video(video_frames)
其他的社区开源文生视频项目
最后,还有各种不在 Hub 上的开源项目和模型。一些值得关注的有 Phil Wang (即 lucidrains) 的 Imagen 非官方实现、Phenaki、NUWA, Make-a-Video 以及 Video Diffusion 模型。还有一个有意思的项目 ExponentialML,它是基于 ![]() Diffusers 的,用于微调 ModelScope 文生视频模型。
Diffusers 的,用于微调 ModelScope 文生视频模型。
总结
文生视频的研究正在呈指数级发展,但现有工作在上下文一致性上仍有限制,同时还面临其他诸多挑战。在这篇博文中,我们介绍了文生视频模型的限制、独特挑战和当前状态。我们还看到了最初为其他任务设计的架构范例如何赋能文生视频任务的巨大飞跃,以及这对未来研究意味着什么。虽然进展令人印象深刻,但与文生图模型相比,文生视频模型还有很长的路要走。最后,我们还展示了如何通过 Hub 上的应用演示来使用这些模型,以及如何将这些模型作为 ![]() Diffusers 流水线的一部分来完成各种任务。
Diffusers 流水线的一部分来完成各种任务。
本文就到此为止了!我们将继续整合最具影响力的计算机视觉和多模态模型,并希望收到你的反馈。要了解计算机视觉和多模态研究的最新消息,你可以在 Twitter 上关注我们: @adirik、@a_e_roberts、@osanviero、@risingsayak 以及 @huggingface。
英文原文: A Dive into Text-to-Video Models
原文作者: Alara Dirik
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
排版/审校: zhongdongy (阿东)