HumanEval 是一个用于评估大型语言模型 (LLM) 在代码生成任务中的参考基准,因为它使得对紧凑的函数级代码片段的评估变得容易。然而,关于其在评估 LLM 编程能力方面的有效性越来越多的担忧,主要问题是HumanEval 中的任务太简单,可能不能代表真实世界的编程任务。相比于 HumanEval 中的算法导向任务,真实世界的软件开发通常涉及多样的库和函数调用。此外,LLM 在 HumanEval 上的表现还受 污染和过拟合问题 的影响,这使得其在评估 LLM 的泛化能力方面不够可靠。
虽然已经有一些努力来解决这些问题,但它们要么是特定领域的、确定性的,要么是以大模型代理为中心的 (抱歉,DS-1000、ODEX 和 SWE-bench ![]() )。我们觉得社区仍然缺乏一个可以广泛评估 LLM 编程能力的易用基准,这正是我们关注的重点。
)。我们觉得社区仍然缺乏一个可以广泛评估 LLM 编程能力的易用基准,这正是我们关注的重点。
我们很高兴宣布 BigCodeBench 的发布,它可以在没有污染的情况下评估 LLM 解决实际和具有挑战性的编程任务的能力。具体来说,BigCodeBench 包含 1140 个函数级任务,挑战 LLM 遵循指令并将来自 139 个库的多个函数调用作为工具进行组合。为了严格评估 LLM,每个编程任务包含 5.6 个测试用例,平均分支覆盖率为 99%。
准备好深入了解 BigCodeBench 了吗?让我们开始吧!![]()
BigCodeBench 中的任务是什么样的?

BigCodeBench 为每个任务提供了复杂的、面向用户的指令,包括清晰的功能描述、输入/输出格式、错误处理和已验证的交互示例。我们避免逐步的任务指令,相信有能力的 LLM 应该能够从用户的角度以开放的方式理解和解决任务。我们通过测试用例验证特定功能。
# 我们用一些测试用例来详细说明上述任务:
# 设置需求
import unittest
from unittest.mock import patch
import http.client
import ssl
import socket
# 开始测试
class TestCases(unittest.TestCase):
# 模拟成功连接并评估响应内容
@patch('http.client.HTTPSConnection')
def test_response_content(self, mock_conn):
""" 测试响应内容。 """
mock_conn.return_value.getresponse.return_value.read.return_value = b'Expected Content'
result = task_func('www.example.com', 443, '/content/path')
self.assertEqual(result, 'Expected Content')
# 模拟连接失败并评估错误处理
@patch('socket.create_connection')
@patch('http.client.HTTPSConnection')
def test_ssl_handshake_error_handling(self, mock_conn, mock_socket):
""" 测试 SSL 握手错误的处理。 """
mock_socket.side_effect = ssl.SSLError('SSL handshake failed')
with self.assertRaises(ssl.SSLError):
task_func('badssl.com', 443, '/test/path')
# 更多测试用例...
BigCodeBench 中的任务利用了来自流行库的多样化函数调用。我们不限制 LLM 可以使用的函数调用,期望它们选择适当的函数并灵活组合以解决任务。测试用例设计为测试框架,以在运行时检查预期的程序行为。
为了评估 LLM 的表现,我们使用贪婪解码的 Pass@1,测量通过精心设计的测试用例生成的第一个代码片段正确解决任务的百分比。这个方法与 HumanEval 和 MBPP 等基准保持一致。我们通过在 Pass@1 评估期间添加缺失的设置 (例如导入语句,全局常量) 来解决 LLM 跳过长代码提示的倾向,这被称为校准的 Pass@1。

为了更好地理解实现的复杂性和工具使用的多样性,我们将 BigCodeBench 中的任务与代表性基准的任务进行了比较,包括 APPS、DS-1000、ODEX、APIBench、MBPP、NumpyEval、PandasEval、HumanEval 和 TorchDataEval。我们发现 BigCodeBench 需要更复杂的推理和问题解决技能来实现全面的功能。

如任务图所示,主要目标场景是代码完成 (记为 BigCodeBench-Complete),LLM 需要根据文档字符串中的详细指令完成函数的实现。然而,考虑到下游应用程序如多轮对话,用户可能会以更对话化和不那么冗长的方式描述需求。这就是指令调整的 LLM 有用的地方,因为它们经过训练可以遵循自然语言指令并相应地生成代码片段。为了测试模型是否真的能理解人类意图并将其转化为代码,我们创建了 BigCodeBench-Instruct,这是 BigCodeBench 的一个更具挑战性的变体,旨在评估指令调整的 LLM。
这些任务来自哪里?

我们通过系统的“人类-LLM 协作过程”来保证 BigCodeBench 中任务的质量。我们以 ODEX 作为“种子数据集”,其中包含了来自 Stack Overflow 的简短但现实的人工意图和相应的 Python 一行代码。我们使用 GPT-4 将这些一行代码扩展为全面的函数级任务。
接下来,20 位拥有超过 5 年 Python 编程经验的志愿专家在基于执行的沙箱中指导 GPT-4。他们不断指示 GPT-4 完善生成的任务并添加测试用例。然后在本地环境中检查这些任务和测试用例,在其他 LLM 上进行预评估,并由另外 7 位人类专家交叉检查以确保其质量。
为了确保整体质量,作者抽样了任务让 11 位人类专家解决,平均人类表现为 97%。
各 LLM 在 BigCodeBench 上的表现如何?
我们在 Hugging Face Space 和 GitHub Pages 上托管 BigCodeBench 排行榜。以下是 Hugging Face 排行榜的示例。
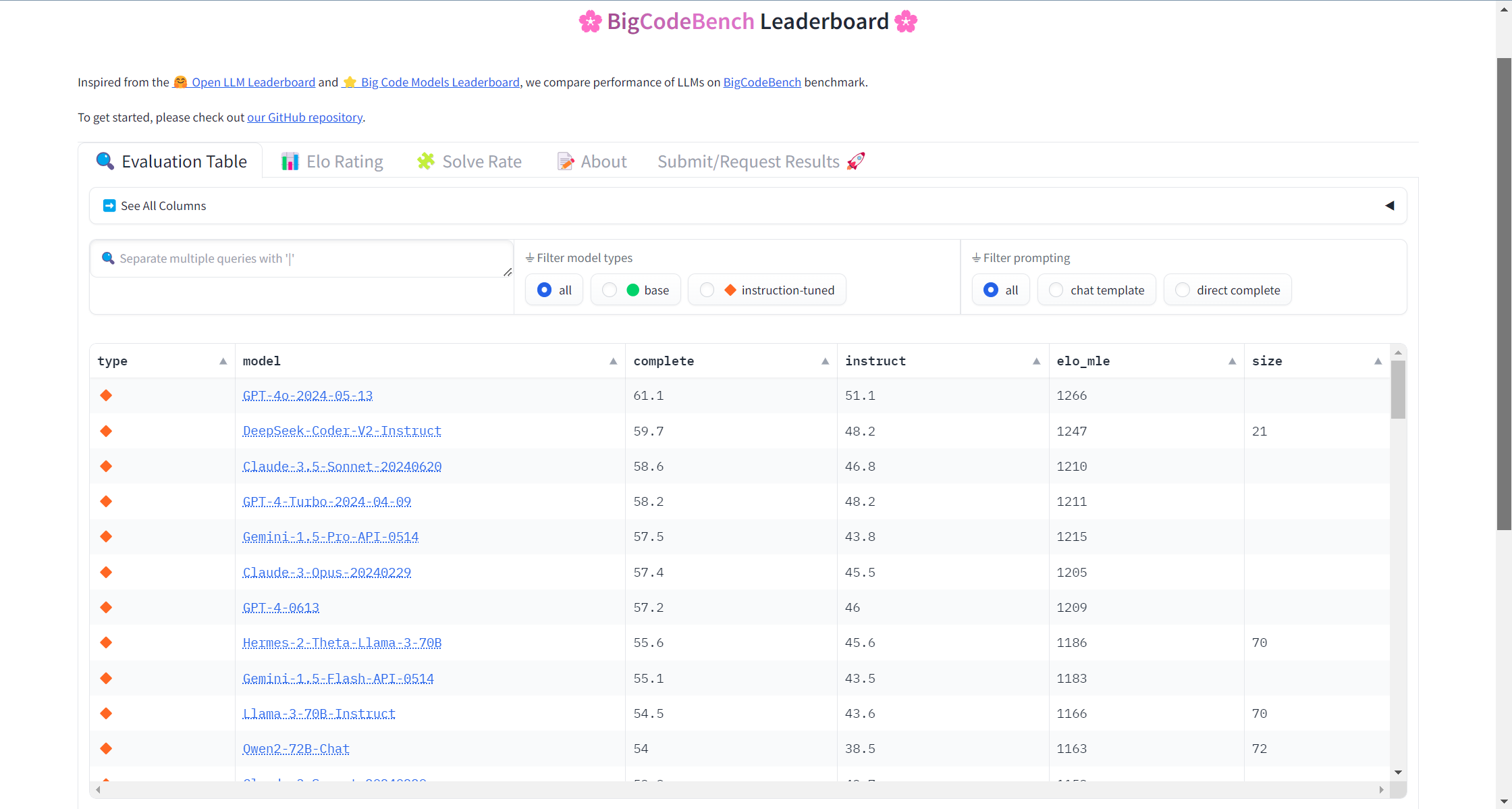
有趣的是,我们观察到像 GPT-4 这样的指令调整 LLM 在 BigCodeBench-Complete 的长提示中会省略必要的导入语句,导致由于缺少模块和常量而导致的任务失败。这种行为被称为“模型懒惰”,在 社区 中有讨论。
与人类表现相比,LLM 在 BigCodeBench-Complete 上的表现显著低于人类表现,在BigCodeBench-Instruct上的表现甚至更低。 最佳模型 (GPT-4o) 在 BigCodeBench-Complete 上的校准 Pass@1 为 61.1%,在 BigCodeBench-Instruct 上的校准 Pass@1 为 51.1%。此外,封闭式 LLM 和开放式 LLM 之间的表现差距显著。
虽然 Pass@1 是评估整体表现的好指标,但它不足以直接比较模型。受到 Chatbot Arena 的启发,我们使用 Elo 评分来对 BigCodeBench-Complete 上的模型进行排名。该方法最初用于国际象棋,根据玩家的比赛表现进行排名。我们将其适应于编程任务,将每个任务视为一场比赛,每个模型视为一个玩家。Elo 评分更新基于比赛结果和预期,使用任务级校准 Pass@1 (0%或100%),排除平局。我们从初始 Elo 评分 1000 开始,使用最大似然估计和 500 次自举来获得最终分数。我们发现 GPT-4o 远远领先于其他模型,DeepSeekCoder-V2 位居第二梯队。
为了帮助社区了解每个任务上的模型表现,我们跟踪解决率,通过校准 Pass@1 测量。在 BigCodeBench-Complete 上,149 个任务被所有模型解决,而 6 个任务被完全解决。在 BigCodeBench-Instruct 上,278 个任务未被解决,14 个任务被所有模型完全解决。大量未解决的任务和少量完全解决的任务表明,BigCodeBench 对 LLM 来说是一个具有挑战性的基准。
太好了!那么,我如何在 BigCodeBench 上评估我的模型?
我们通过提供一个简单易用的评估框架,使 BigCodeBench 对社区易于访问,可以通过 PyPI 下载。评估框架的原型基于 EvalPlus 用于 HumanEval+ 和 MBPP+ 基准。然而,由于我们的基准任务比 EvalPlus 有更多样的库依赖性,我们构建了资源约束更少的执行环境,并适应于 BigCodeBench 的 unittest 测试框架。
为了便于评估,我们提供了预构建的 Docker 镜像用于 代码生成 和 代码执行。请查看我们的 GitHub 仓库,了解如何使用评估框架的更多细节。
设置
# 安装以使用bigcodebench.evaluate
pip install bigcodebench --upgrade
# 如果你想在本地使用 evaluate,你需要安装要求
pip install -I -r https://raw.githubusercontent.com/bigcode-project/bigcodebench/main/Requirements/requirements-eval.txt
# 安装以使用 bigcodebench.generate
# 强烈建议在单独的环境中安装[generate]依赖
pip install bigcodebench[generate] --upgrade
代码生成
建议使用 flash-attn 生成代码样本。
pip install -U flash-attn
要从模型生成代码样本,可以使用以下命令:
bigcodebench.generate \
--model [model_name] \
--subset [complete|instruct] \
--greedy \
--bs [bs] \
--temperature [temp] \
--n_samples [n_samples] \
--resume \
--backend [vllm|hf|openai|mistral|anthropic|google] \
--tp [gpu_number] \
[--trust_remote_code] \
[--base_url [base_url]]
生成的代码样本将存储在名为 [model_name]--bigcodebench-[instruct|complete]--[backend]-[temp]-[n_samples].jsonl 的文件中。
代码后处理
LLM 生成的文本可能不是可编译代码,因为它包含自然语言行或不完整的额外代码。
我们提供一个名为 bigcodebench.sanitize 的工具来清理代码:
# 💡 如果你想在jsonl中存储校准代码:
bigcodebench.sanitize --samples samples.jsonl --calibrate
# 校准后的代码将生成到`samples-sanitized-calibrated.jsonl`
# 💡 如果你不进行校准:
bigcodebench.sanitize --samples samples.jsonl
# 清理后的代码将生成到`samples-sanitized.jsonl`
# 💡 如果你将代码存储在目录中:
bigcodebench.sanitize --samples /path/to/vicuna-[??]b_temp_[??]
# 清理后的代码将生成到`/path/to/vicuna-[??]b_temp_[??]-sanitized`
代码评估
强烈建议使用沙箱如 docker:
# 将当前目录挂载到容器
docker run -v $(pwd):/app bigcodebench/bigcodebench-evaluate:latest --subset [complete|instruct] --samples samples-sanitized-calibrated
# ...或者本地⚠️
bigcodebench.evaluate --subset [complete|instruct] --samples samples-sanitized-calibrated
# ...如果地面真值在本地工作 (由于一些不稳定的测试)
bigcodebench.evaluate --subset [complete|instruct] --samples samples-sanitized-calibrated --no-gt
接下来是什么?
我们分享一个长期路线图,以解决 BigCodeBench 的局限性,并与社区一起可持续发展。我们的目标是为社区提供最开放、最可靠和可扩展的评估,以真正了解 LLM 在编程方面的基本能力,并找到释放其潜力的方法。具体来说,我们计划增强 BigCodeBench 的以下方面:
-
多语言性: 目前,BigCodeBench 仅支持 Python,无法轻松扩展到其他编程语言。由于函数调用大多是特定于语言的,在 Python 以外的语言中找到具有相同功能的包或库是一个挑战。
-
严格性: 虽然我们在 BigCodeBench 的地面真值解决方案中实现了高测试覆盖率,但这并不能保证 LLM 生成的所有代码解决方案都能正确评估现有的测试用例。以前的工作如 EvalPlus 尝试通过 LLM 和基于突变的策略扩展有限的测试用例。然而,将EvalPlus 适应于 BigCodeBench 的测试框架是一个挑战。尽管 EvalPlus 强调输入输出断言,BigCodeBench 中的大多数测试框架需要非平凡的配置 (例如模拟修补) 以在运行时检查预期的程序行为。
-
泛化性: 一个关键问题是,“模型在看不见的工具和任务上的泛化能力如何?”目前,BigCodeBench 涵盖了常见库和日常编程任务。在使用新兴库 (如 transformers 和 langchain) 的编程任务上对模型进行基准测试会更有趣。
-
演化: 库可能会变得过时或被更新,这意味着模型训练的数据会不断演变。模型可能不会记住过时库版本的函数调用,这对任何工具依赖的编程基准来说都是一个挑战,需要定期更新以正确评估模型能力。另一个相关问题是由于训练数据的演变导致的测试集污染。
-
交互: 最近的兴趣集中在 LLM 作为代理的概念上,这被视为通向人工通用智能的途径。具体来说,LLM 将在一个不受限制的沙箱环境中运行,在那里它们可以与网页浏览器和终端等应用程序进行交互。这种环境可以帮助解锁诸如 自我调试 和 自我反思 等能力。
我们很期待看到社区的反馈和对长期建设 BigCodeBench 的贡献![]()
资源
我们开源了 BigCodeBench 的所有工件,包括任务、测试用例、评估框架和排行榜。你可以在以下链接中找到它们:
如果你有任何问题
或建议,请随时在仓库中提交问题或通过 [email protected] 或 [email protected] 联系我们。
引用
如果你觉得我们的评估有用,请考虑引用我们的工作
@article{zhuo2024bigcodebench,
title={BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions},
author={Zhuo, Terry Yue and Vu, Minh Chien and Chim, Jenny and Hu, Han and Yu, Wenhao and Widyasari, Ratnadira and Yusuf, Imam Nur Bani and Zhan, Haolan and He, Junda and Paul, Indraneil and others},
journal={arXiv preprint arXiv:2406.15877},
year={2024}
}
原文链接: https://hf.co/blog/leaderboard-bigcodebench
原文作者: Terry Yue Zhuo, Jiawei Liu, Qian Liu, Binyuan Hui, Niklas Muennighoff, Daniel Fried, Harm de Vries, Leandro von Werra, Clémentine Fourrier
译者: Terry Yue Zhuo