前一段时间,我们向大家介绍了最新一代的 英特尔至强 CPU (代号 Sapphire Rapids),包括其用于加速深度学习的新硬件特性,以及如何使用它们来加速自然语言 transformer 模型的 分布式微调 和 推理。
本文将向你展示在 Sapphire Rapids CPU 上加速 Stable Diffusion 模型推理的各种技术。后续我们还计划发布对 Stable Diffusion 进行分布式微调的文章。
在撰写本文时,获得 Sapphire Rapids 服务器的最简单方法是使用 Amazon EC2 R7iz 系列实例。由于它仍处于预览阶段,你需要 注册 才能获得访问权限。与之前的文章一样,我使用的是 r7iz.metal-16xl 实例 (64 个 vCPU,512GB RAM),操作系统镜像为 Ubuntu 20.04 AMI (ami-07cd3e6c4915b2d18)。
本文的代码可从 Gitlab 上获取。我们开始吧!
Diffusers 库
Diffusers 库使得用 Stable Diffusion 模型生成图像变得极其简单。如果你不熟悉 Stable Diffusion 模型,这里有一个很棒的 图文介绍。
首先,我们创建一个包含以下库的虚拟环境: Transformers、Diffusers、Accelerate 以及 PyTorch。
virtualenv sd_inference
source sd_inference/bin/activate
pip install pip --upgrade
pip install transformers diffusers accelerate torch==1.13.1
然后,我们写一个简单的基准测试函数,重复推理多次,最后返回单张图像生成的平均延迟。
import time
def elapsed_time(pipeline, prompt, nb_pass=10, num_inference_steps=20):
# warmup
images = pipeline(prompt, num_inference_steps=10).images
start = time.time()
for _ in range(nb_pass):
_ = pipeline(prompt, num_inference_steps=num_inference_steps, output_type="np")
end = time.time()
return (end - start) / nb_pass
现在,我们用默认的 float32 数据类型构建一个 StableDiffusionPipeline,并测量其推理延迟。
from diffusers import StableDiffusionPipeline
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id)
prompt = "sailing ship in storm by Rembrandt"
latency = elapsed_time(pipe, prompt)
print(latency)
平均延迟为 32.3 秒。正如这个英特尔开发的 Hugging Face Space 所展示的,相同的代码在上一代英特尔至强 (代号 Ice Lake) 上运行需要大约 45 秒。
开箱即用,我们可以看到 Sapphire Rapids CPU 在没有任何代码更改的情况下速度相当快!
现在,让我们继续加速它吧!
Optimum Intel 与 OpenVINO
Optimum Intel 用于在英特尔平台上加速 Hugging Face 的端到端流水线。它的 API 和 Diffusers 原始 API 极其相似,因此所需代码改动很小。
Optimum Intel 支持 OpenVINO,这是一个用于高性能推理的英特尔开源工具包。
Optimum Intel 和 OpenVINO 安装如下:
pip install optimum[openvino]
相比于上文的代码,我们只需要将 StableDiffusionPipeline 替换为 OVStableDiffusionPipeline 即可。如需加载 PyTorch 模型并将其实时转换为 OpenVINO 格式,你只需在加载模型时设置 export=True。
from optimum.intel.openvino import OVStableDiffusionPipeline
...
ov_pipe = OVStableDiffusionPipeline.from_pretrained(model_id, export=True)
latency = elapsed_time(ov_pipe, prompt)
print(latency)
# Don't forget to save the exported model
ov_pipe.save_pretrained("./openvino")
OpenVINO 会自动优化 bfloat16 模型,优化后的平均延迟下降到了 16.7 秒,相当不错的 2 倍加速。
上述 pipeline 支持动态输入尺寸,对输入图像 batch size 或分辨率没有任何限制。但在使用 Stable Diffusion 时,通常你的应用程序仅限于输出一种 (或几种) 不同分辨率的图像,例如 512x512 或 256x256。因此,通过固定 pipeline 的输出分辨率来解锁更高的性能增益有其实际意义。如果你需要不止一种输出分辨率,您可以简单地维护几个 pipeline 实例,每个分辨率一个。
ov_pipe.reshape(batch_size=1, height=512, width=512, num_images_per_prompt=1)
latency = elapsed_time(ov_pipe, prompt)
固定输出分辨率后,平均延迟进一步降至 4.7 秒,又获得了额外的 3.5 倍加速。
如你所见,OpenVINO 是加速 Stable Diffusion 推理的一种简单有效的方法。与 Sapphire Rapids CPU 结合使用时,和至强 Ice Lake 的最初性能的相比,推理性能加速近 10 倍。
如果你不能或不想使用 OpenVINO,本文下半部分会展示一系列其他优化技术。系好安全带!
系统级优化
扩散模型是数 GB 的大模型,图像生成是一种内存密集型操作。通过安装高性能内存分配库,我们能够加速内存操作并使之能在 CPU 核之间并行处理。请注意,这将更改系统的默认内存分配库。你可以通过卸载新库来返回默认库。
jemalloc 和 tcmalloc 是两个很有意思的内存优化库。这里,我们使用 jemalloc,因为我们测试下来,它的性能比 tcmalloc 略好。 jemalloc 还可以用于针对特定工作负载进行调优,如最大化 CPU 利用率。详情可参考 jemalloc调优指南。
sudo apt-get install -y libjemalloc-dev
export LD_PRELOAD=$LD_PRELOAD:/usr/lib/x86_64-linux-gnu/libjemalloc.so
export MALLOC_CONF="oversize_threshold:1,background_thread:true,metadata_thp:auto,dirty_decay_ms: 60000,muzzy_decay_ms:60000"
接下来,我们安装 libiomp 库来优化多核并行,这个库是 英特尔 OpenMP 运行时库 的一部分。
sudo apt-get install intel-mkl
export LD_PRELOAD=$LD_PRELOAD:/usr/lib/x86_64-linux-gnu/libiomp5.so
export OMP_NUM_THREADS=32
最后,我们安装 numactl 命令行工具。它让我们可以把我们的 Python 进程绑定到指定的核,并避免一些上下文切换开销。
numactl -C 0-31 python sd_blog_1.py
使用这些优化后,原始的 Diffusers 代码只需 11.8 秒 就可以完成推理,快了几乎 3 倍,而且无需任何代码更改。这些工具在我们的 32 核至强 CPU 上运行得相当不错。
我们还有招。现在我们把 英特尔 PyTorch 扩展 (Intel Extension for PyTorch, IPEX) 引入进来。
IPEX 与 BF16
IPEX 扩展了 PyTorch 使之可以进一步充分利用英特尔 CPU 上的硬件加速功能,包括 AVX-512 、矢量神经网络指令 (Vector Neural Network Instructions,AVX512 VNNI) 以及 先进矩阵扩展 (AMX)。
我们先安装 IPEX。
pip install intel_extension_for_pytorch==1.13.100
装好后,我们需要修改部分代码以将 IPEX 优化应用到 pipeline 的每个模块 (你可以通过打印 pipe 对象罗列出它有哪些模块),其中之一的优化就是把数据格式转换为 channels-last 格式。
import torch
import intel_extension_for_pytorch as ipex
...
pipe = StableDiffusionPipeline.from_pretrained(model_id)
# to channels last
pipe.unet = pipe.unet.to(memory_format=torch.channels_last)
pipe.vae = pipe.vae.to(memory_format=torch.channels_last)
pipe.text_encoder = pipe.text_encoder.to(memory_format=torch.channels_last)
pipe.safety_checker = pipe.safety_checker.to(memory_format=torch.channels_last)
# Create random input to enable JIT compilation
sample = torch.randn(2,4,64,64)
timestep = torch.rand(1)*999
encoder_hidden_status = torch.randn(2,77,768)
input_example = (sample, timestep, encoder_hidden_status)
# optimize with IPEX
pipe.unet = ipex.optimize(pipe.unet.eval(), dtype=torch.bfloat16, inplace=True, sample_input=input_example)
pipe.vae = ipex.optimize(pipe.vae.eval(), dtype=torch.bfloat16, inplace=True)
pipe.text_encoder = ipex.optimize(pipe.text_encoder.eval(), dtype=torch.bfloat16, inplace=True)
pipe.safety_checker = ipex.optimize(pipe.safety_checker.eval(), dtype=torch.bfloat16, inplace=True)
我们使用了 bloat16 数据类型,以利用 Sapphire Rapids CPU 上的 AMX 加速器。
with torch.cpu.amp.autocast(enabled=True, dtype=torch.bfloat16):
latency = elapsed_time(pipe, prompt)
print(latency)
经过此番改动,推理延迟从 11.9 秒进一步减少到 5.4 秒。感谢 IPEX 和 AMX,推理速度提高了 2 倍以上。
还能榨点性能出来吗?能,我们将目光转向调度器 (scheduler)!
调度器
Diffusers 库支持为每个 Stable Diffusion pipiline 配置 调度器 (scheduler),用于在去噪速度和去噪质量之间找到最佳折衷。
根据文档所述: “ 截至本文档撰写时,DPMSolverMultistepScheduler 能实现最佳的速度/质量权衡,只需 20 步即可运行。” 我们可以试一下 DPMSolverMultistepScheduler。
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
...
dpm = DPMSolverMultistepScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=dpm)
最终,推理延迟降至 5.05 秒。与我们最初的 Sapphire Rapids 基线 (32.3 秒) 相比,几乎快了 6.5 倍!
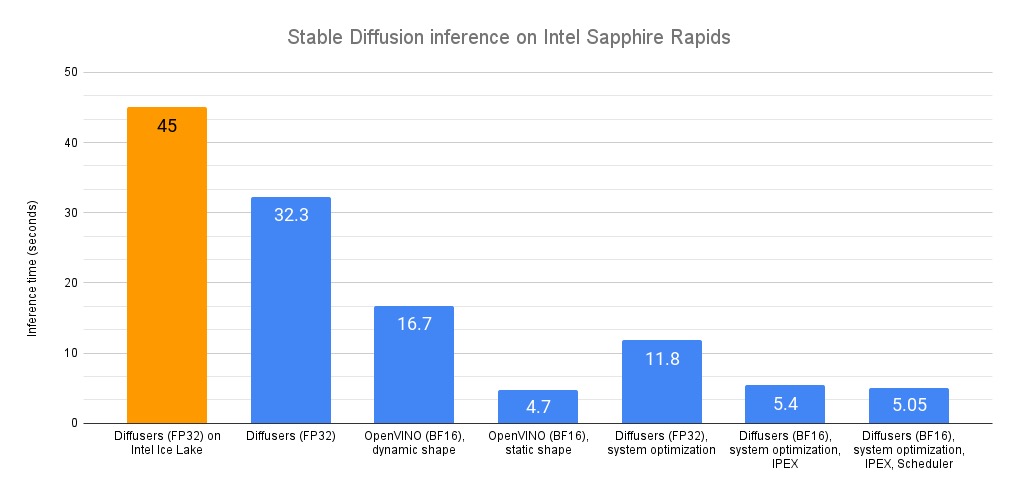
运行环境: Amazon EC2 r7iz.metal-16xl, Ubuntu 20.04, Linux 5.15.0-1031-aws, libjemalloc-dev 5.2.1-1, intel-mkl 2020.0.166-1, PyTorch 1.13.1, Intel Extension for PyTorch 1.13.1, transformers 4.27.2, diffusers 0.14, accelerate 0.17.1, openvino 2023.0.0.dev20230217, optimum 1.7.1, optimum-intel 1.7
总结
在几秒钟内生成高质量图像的能力可用于许多场景,如 2C 的应用程序、营销和媒体领域的内容生成,或生成合成数据以扩充数据集。
如你想要在这方面起步,以下是一些有用的资源:
- Diffusers 文档
- Optimum Intel 文档
- 英特尔 IPEX on GitHub
- 英特尔和 Hugging Face 联合出品的开发者资源网站
如果你有任何问题或反馈,请通过 Hugging Face 论坛 告诉我们。
感谢垂阅!
英文原文: https://hf.co/blog/stable-diffusion-inference-intel
作者: Julien Simon, Ella Charlaix
译者: MatrixYao
审校/排版: zhongdongy (阿东)