社区中有两个流行的 零冗余优化器(Zero Redundancy Optimizer,ZeRO) 算法实现,一个来自 DeepSpeed,另一个来自 PyTorch。Hugging Face Accelerate 对这两者都进行了集成并通过接口暴露出来,以供最终用户在训练/微调模型时自主选择其中之一。本文重点介绍了 Accelerate 对外暴露的这两个后端之间的差异。为了让用户能够在这两个后端之间无缝切换,我们在 Accelerate 中合并了 一个精度相关的 PR 及 一个新的概念指南。
FSDP 和 DeepSpeed 可以互换吗?
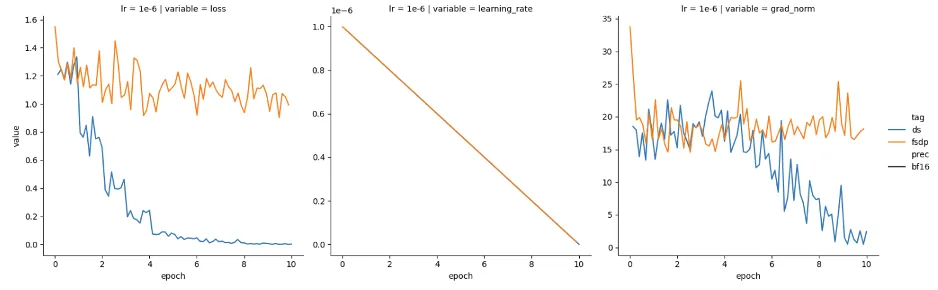
最近,我们尝试分别使用 DeepSpeed 和 PyTorch FSDP 进行训练,发现两者表现有所不同。我们使用的是 Mistral-7B 基础模型,并以半精度(bfloat16)加载。可以看到 DeepSpeed(蓝色)损失函数收敛良好,但 FSDP(橙色)损失函数没有收敛,如图 1 所示。
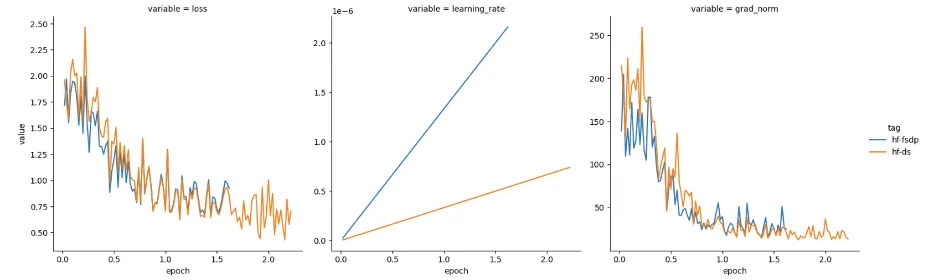
我们猜想可能需要根据 GPU 数量对学习率进行缩放,且由于我们使用了 4 个 GPU,于是我们将学习率提高了 4 倍。然后,损失表现如图 2 所示。
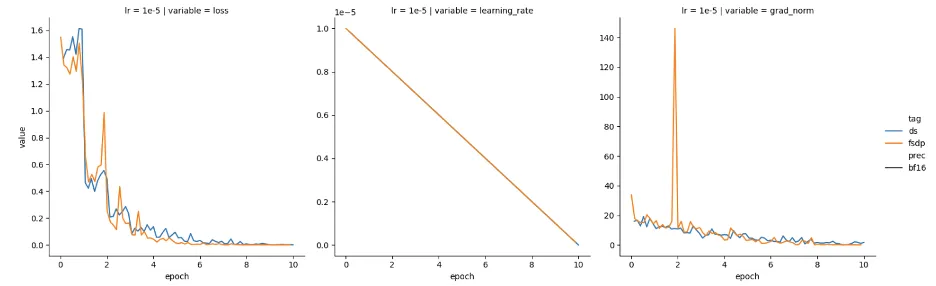
看起来,通过按 GPU 数量缩放 FSDP 学习率,已经达到了预期!然而,当我们在不进行缩放的情况下尝试其他学习率(1e-5)时,我们却又观察到这两个框架的损失和梯度范数特征又是趋近一致的,如图 3 所示。
精度很重要
在 DeepSpeed 代码库的 DeepSpeedZeroOptimizer_Stage3(顾名思义,处理第 3 阶段优化器分片)实现代码中,我们注意到 trainable_param_groups(可训参数组)被传入一个内部函数 _setup_for_real_optimizer,该函数会调用另一个名为 _create_fp32_partitions 的函数。正如其名称中的 fp32 所示,DeepSpeed 内部执行了精度上转,并在设计上始终将主权重保持为 fp32 精度。而上转至全精度意味着:同一个学习率,上转后的优化器可以收敛,而原始低精度下的优化器则可能不会收敛。前述现象就是这种精度差异的产物。
在 FSDP 中,在把模型和优化器参数分片到各 GPU 上之前,这些参数首先会被“展平”为一维张量。FSDP 和 DeepSpeed 对这些“展平”参数使用了不同的 dtype,这会影响 PyTorch 优化器的表现。表 1 概述了两个框架各自的处理流程,“本地?”列说明了当前步骤是否是由各 GPU 本地执行的,如果是这样的话,那么上转的内存开销就可以分摊到各个 GPU。
| 流程 | 本地? | 框架 | 详情 |
|---|---|---|---|
模型加载(如 AutoModel.from_pretrained(..., torch_dtype=torch_dtype)) |
|||
| 准备,如创建“展平参数” | FSDP DeepSpeed |
使用 torch_dtype不管 torch_dtype,直接创建为 float32 |
|
| 优化器初始化 | FSDP DeepSpeed |
用 torch_dtype 创建参数用 float32 创建参数 |
|
| 训练步(前向、后向、归约) | FSDP DeepSpeed |
遵循 fsdp.MixedPrecision 遵循 deepspeed_config_file 中的混合精度设置 |
|
| 优化器(准备阶段) | FSDP DeepSpeed |
按需上转至 torch_dtype所有均上转至 float32 |
|
| 优化器(实际执行阶段) | FSDP DeepSpeed |
以 torch_dtype 精度进行以 float32 精度进行 |
表 1: FSDP 与 DeepSpeed 混合精度处理异同
几个要点:
- 正如
 Accelerate 上的这一问题所述,混合精度训练的经验法则是将可训参数精度保持为
Accelerate 上的这一问题所述,混合精度训练的经验法则是将可训参数精度保持为 float32。 - 当在大量 GPU 上进行分片时,上转(如
DeepSpeed中所做的那样)对内存消耗的影响可能可以忽略不计。然而,当在少量 GPU 上使用DeepSpeed时,内存消耗会显著增加,高达 2 倍。 - FSDP 的 PyTorch 原生实现不会强制上转,其支持用户以低精度操作 PyTorch 优化器,因此相比
DeepSpeed提供了更大的灵活性。
在 Accelerate 中对齐 DeepSpeed 和 FSDP 的行为
为了在![]() Accelerate 中更好地对齐 DeepSpeed 和 FSDP 的行为,我们可以在启用混合精度时自动对 FSDP 执行上转。我们为此做了一个 PR,该 PR 现已包含在 0.30.0 版本中了。
Accelerate 中更好地对齐 DeepSpeed 和 FSDP 的行为,我们可以在启用混合精度时自动对 FSDP 执行上转。我们为此做了一个 PR,该 PR 现已包含在 0.30.0 版本中了。
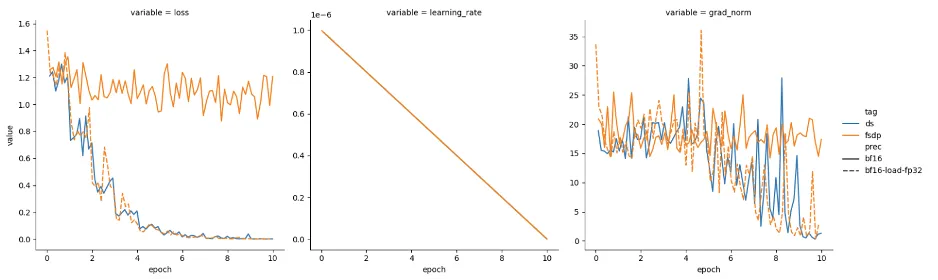
有了这个 PR,FSDP 就能以两种模式运行:
- 与 DeepSpeed 一致的
混合精度模式 - 针对内存受限场景的低精度模式,如图 4 所示。
表 2 总结了两种新的 FSDP 模式,并与 DeepSpeed 进行了比较。
| 框架 | 模型加载 (torch_dtype) |
混合精度 | 准备(本地) | 训练 | 优化器(本地) |
|---|---|---|---|---|---|
| FSDP(低精度模式) | bf16 |
缺省(无) | bf16 |
bf16 |
bf16 |
| FSDP(混合精度模式) | bf16 |
bf16 |
fp32 |
bf16 |
fp32 |
| DeepSpeed | bf16 |
bf16 |
fp32 |
bf16 |
fp32 |
表 2:两种新 FSDP 模式总结及与 DeepSpeed 的对比
吞吐量测试结果
我们使用 IBM Granite 7B 模型(其架构为 Meta Llama2)进行吞吐量比较。我们比较了模型的浮点算力利用率 (Model Flops Utilization,MFU) 和每 GPU 每秒词元数这两个指标,并针对 FSDP(完全分片)和 DeepSpeed(ZeRO3)两个场景进行了测量。
如上文,我们使用 4 张 A100 GPU,超参如下:
- batch size 为 8
- 模型加载为
torch.bfloat16 - 使用
torch.bfloat16混合精度
表 3 表明 FSDP 和 DeepSpeed 的表现类似,这与我们的预期相符。
随着大规模对齐技术(如 InstructLab 及 GLAN)的流行,我们计划对结合各种提高吞吐量的方法(如,序列组装 + 4D 掩码、torch.compile、选择性 checkpointing)进行全面的吞吐量对比基准测试。
| 框架 | 每 GPU 每秒词元数 | 每步耗时(s) | 浮点算力利用率(MFU) |
|---|---|---|---|
| FSDP(混合精度模式) | 3158.7 | 10.4 | 0.41 |
| DeepSpeed | 3094.5 | 10.6 | 0.40 |
表 3:四张 A100 GPU 上 FSDP 和 DeepSpeed 之间的大致吞吐量比较。
最后的话
我们提供了新的 概念指南 以帮助用户在两个框架之间迁移。该指南可以帮助用户厘清以下问题:
- 如何实现等效的分片策略?
- 如何进行高效的模型加载?
- FSDP 和 DeepSpeed 中如何管理权重预取?
- 与 DeepSpeed 对等的 FSDP 封装是什么?
我们在 ![]() Accelerate 中考虑了配置这些框架的各种方式:
Accelerate 中考虑了配置这些框架的各种方式:
![]() Accelerate 使得在 FSDP 和 DeepSpeed 之间切换非常丝滑,大部分工作都只涉及更改 Accelerate 配置文件(有关这方面的说明,请参阅新的概念指南)。
Accelerate 使得在 FSDP 和 DeepSpeed 之间切换非常丝滑,大部分工作都只涉及更改 Accelerate 配置文件(有关这方面的说明,请参阅新的概念指南)。
除了配置变更之外,还有一些如检查点处理方式的差异等,我们一并在指南中进行了说明。
本文中的所有实验都可以使用 原始 ![]() Accelerate 问题 中的代码重现。
Accelerate 问题 中的代码重现。
我们计划后续在更大规模 GPU 上进行吞吐量比较,并对各种不同技术进行比较,以在保持模型质量的前提下更好地利用更多的 GPU 进行微调和对齐。
致谢
本工作凝聚了来自多个组织的多个团队的共同努力。始于 IBM 研究中心,特别是发现该问题的 Aldo Pareja 和发现精度差距并解决该问题的 Fabian Lim。Zach Mueller 和 Stas Bekman 在提供反馈和修复 accelerate 的问题上表现出色。Meta PyTorch 团队的 Less Wright 对有关 FSDP 参数的问题非常有帮助。最后,我们还要感谢 DeepSpeed 团队对本文提供的反馈。
英文原文: https://hf.co/blog/deepspeed-to-fsdp-and-back
原文作者: Yu Chin Fabian, aldo pareja, Zachary Mueller, Stas Bekman
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。