每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新、社区活动、学习资源和内容更新、开源库和模型更新等,我们将其称之为「Hugging News」。本期 Hugging News 有哪些有趣的消息,快来看看吧! ![]()
![]()
重磅更新
庆祝 Hugging Face 模型中心上的一百万个代码仓库!

最近 Hugging Face 又取得一个重要里程碑,我们的模型中心(Hub)上已经拥有一百万个代码仓库了!![]()
![]()
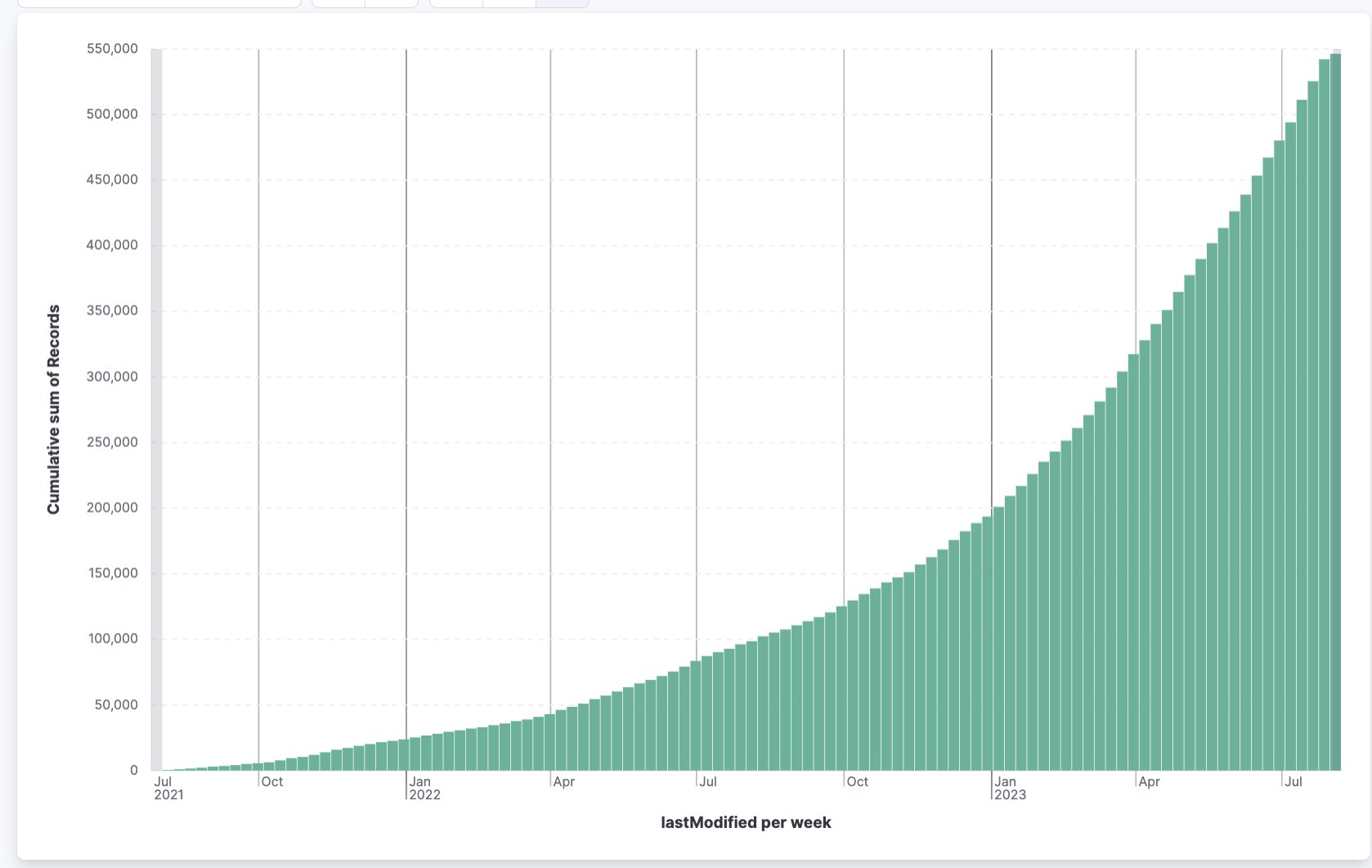
自2023 年 1 月 3 日起我们的模型增长情况:
- 模型:22 万 → 51 万
- 数据集:5 万 → 23 万
- Spaces(空间):3.9 万 → 22 万
这一切都归功于开源的力量!![]()
Accelerate 加速库下载量过 3000 万!
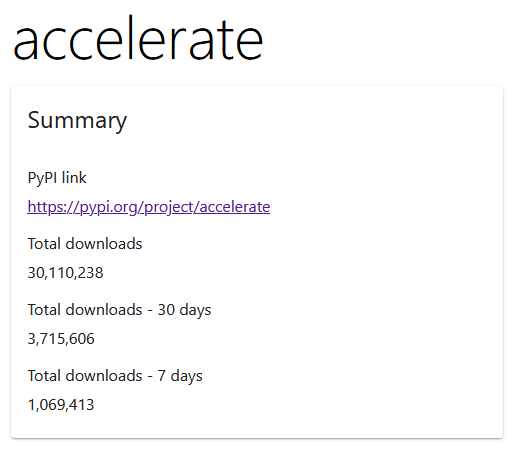
在短短的两个月内,我们的 Hugging Face Accelerate 加速库下载量从 2000 万增长到了 3000 万!看到 PyTorch 生态系统内的增长和使用情况非常令人惊叹,我们对未来的发展充满期待!
![]() Accelerate 加速库是一个能够通过仅添加四行代码在任何分布式配置下运行相同 PyTorch 代码的库!它使得规模化进行训练和推断变得简单、高效且灵活。
Accelerate 加速库是一个能够通过仅添加四行代码在任何分布式配置下运行相同 PyTorch 代码的库!它使得规模化进行训练和推断变得简单、高效且灵活。
![]() Accelerate 加速库基于 torch_xla 和 torch.distributed 构建,负责处理繁重的工作,因此你无需编写任何自定义代码来适应这些平台。将现有代码库转换为使用 DeepSpeed,执行完全分片的数据并行操作,并自动支持混合精度训练!如果想要了解更多关于 Accelerate 加速库的信息,请访问项目:
Accelerate 加速库基于 torch_xla 和 torch.distributed 构建,负责处理繁重的工作,因此你无需编写任何自定义代码来适应这些平台。将现有代码库转换为使用 DeepSpeed,执行完全分片的数据并行操作,并自动支持混合精度训练!如果想要了解更多关于 Accelerate 加速库的信息,请访问项目:
![]() GitHub:https://github.com/huggingface/accelerate
GitHub:https://github.com/huggingface/accelerate
![]() 文档:https://huggingface.co/docs/accelerate/index
文档:https://huggingface.co/docs/accelerate/index
 与 MLCommons 合作推出 MedPerf
与 MLCommons 合作推出 MedPerf

Hugging Face 非常高兴能够与 MLCommons 合作,共同推出一个使用联合评估的医疗基准测试框架 MedPerf ![]()
这个开放的科学倡议已在 NatMachIntell (自然-机器智能杂志)上发表,这是在严格和隐私保护的医疗 AI 模型评估迈出的重要一步。我们相信医疗 AI 领域需要更多的开放科学努力,因此我们很开心能够与20多个学术机构、9家医院和20多家公司一起为这一努力作出贡献。
论文链接:https://nature.com/articles/s42256-023-00652-2
网站链接:https://medperf.org
开源更新
Hugging Face 物体检测排行榜 


非常高兴与大家分享我们的最新创作:物体检测排行榜 ![]()
![]()
![]()
![]() 开放式目标检测排行榜旨在跟踪、排名和评估存储在 Hub 中的视觉模型,这些模型旨在在图像中检测对象。社区中的任何人都可以请求对一个模型进行评估并将其添加到排行榜中。查看
开放式目标检测排行榜旨在跟踪、排名和评估存储在 Hub 中的视觉模型,这些模型旨在在图像中检测对象。社区中的任何人都可以请求对一个模型进行评估并将其添加到排行榜中。查看 ![]() 指标选项卡可以了解如何评估这些模型。
指标选项卡可以了解如何评估这些模型。
如果你想要没有列在此处的模型的结果,可以通过邮件 ![]()
![]() 向我们提出对其结果的请求。如果你有一个模型,也欢迎带过来看看它的表现如何!
向我们提出对其结果的请求。如果你有一个模型,也欢迎带过来看看它的表现如何!![]()
快去看看吧:http://huggingface.co/spaces/rafaelpadilla/object_detection_leaderboard
推出 Agent.js 


我们最近推出了 Agents.js,这是 huggingface.js 库的一个新内容,可以让你通过工具为你的 LLM 提供动力,仅使用 JavaScript 就能实现,可以让你从 JavaScript 中在浏览器或服务器上为 LLM 提供工具访问!![]() 它配备了多模态工具,可以从 Hub 调用推理端点,并且可以轻松地通过你自己的工具和语言模型进行扩展。
它配备了多模态工具,可以从 Hub 调用推理端点,并且可以轻松地通过你自己的工具和语言模型进行扩展。
在这里阅读更多信息:https://huggingface.co/blog/agents-js
用 2 行代码将 Bark 的文本转语音加速 30% 
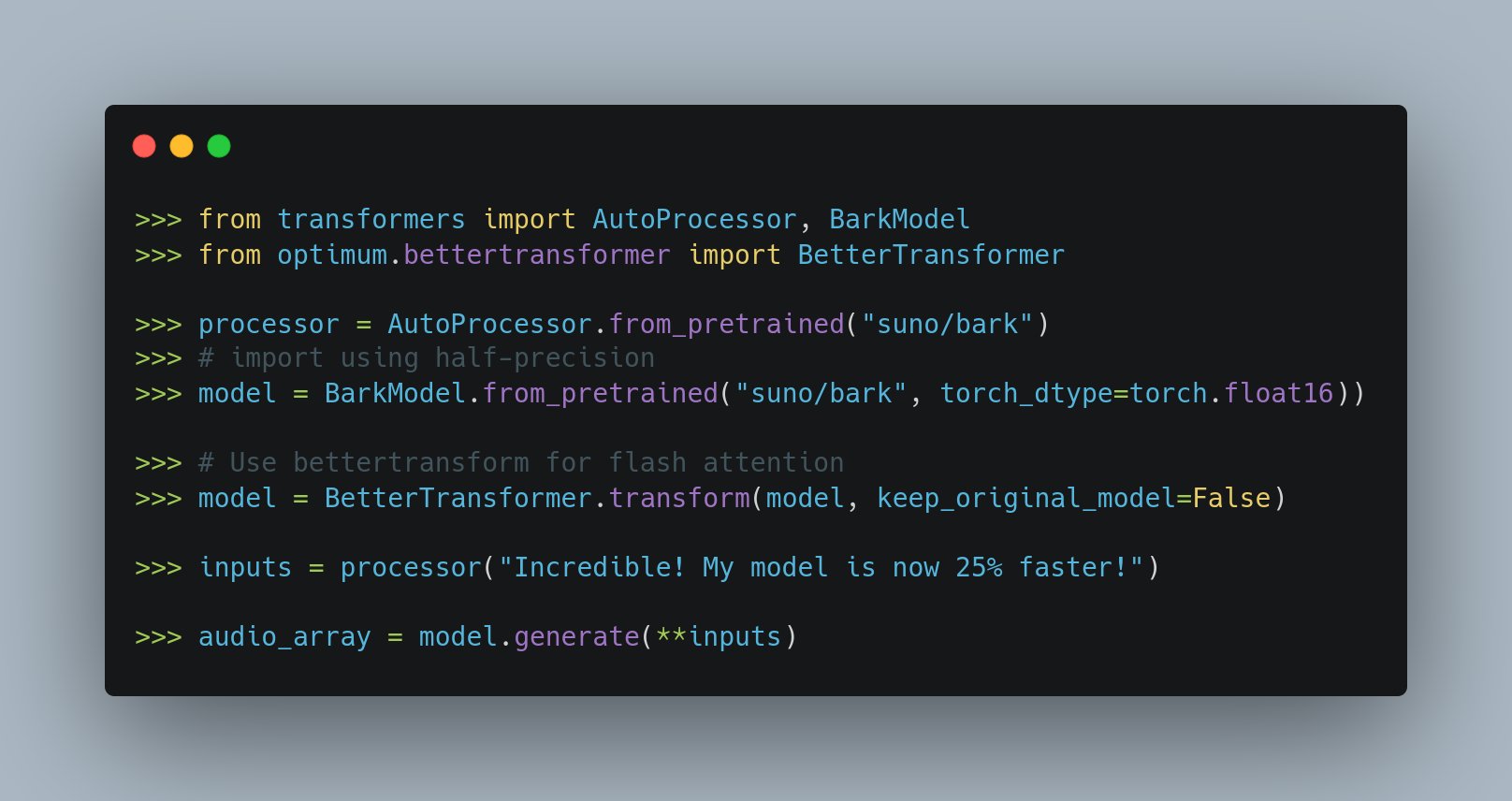
想要加速你的文本转语音生成吗?感谢 Hugging Face 的 Optimum 和半精度,现在你只需两行代码就可以让 Bark 的生成速度提升近 30%!
在这里测试每种优化:https://colab.research.google.com/drive/1XO0RhINg4ZZCdJJmPeJ9lOQs98skJ8h_?usp=sharing
如果你的内存受限,你可以通过只增加一行额外的代码来减少 GPU 的内存占用,将其降低 60% ![]() ,采用 CPU 卸载!你也可以使用批处理获得免费的吞吐量,将批处理设置为 8 并使用 fp16,你可以获得 6 倍的吞吐量,而仅减慢 1.3 倍的速度!
,采用 CPU 卸载!你也可以使用批处理获得免费的吞吐量,将批处理设置为 8 并使用 fp16,你可以获得 6 倍的吞吐量,而仅减慢 1.3 倍的速度!
![]() Bark 是由 Suno AI 在 suno-ai/bark 中提出的基于 transformer 的文本转语音模型。
Bark 是由 Suno AI 在 suno-ai/bark 中提出的基于 transformer 的文本转语音模型。
Bark 由 4 个主要模型组成:
- BarkSemanticModel(也称为“文本”模型):一种因果自回归 transformer 模型。
- BarkCoarseModel(也称为“粗声学”模型):一种因果自回归 transformer,它以 BarkSemanticModel 模型的结果作为输入。它的目标是预测 EnCodec 所需的前两个音频码书。
- BarkFineModel(“细声学”模型),这次是一种非因果自编码 transformer,它基于先前码书嵌入的总和,迭代地预测最后的码书。
- 在预测了 EncodecModel 的所有码书通道后,Bark 使用它来解码输出音频数组。
HF Optimum 是 Hugging Face 开发的一个优化库,旨在提高深度学习模型训练的效率和性能。它自动地为模型选择合适的超参数,如学习率、批大小等,以最大程度地提高训练速度和模型性能。HF Optimum 利用了自动调参技术,通过多次试验不同的超参数组合,找到最优的组合,从而减少了用户手动调参的工作量。
半精度(Half Precision)是一种深度学习训练中的数值表示方式,使用较少的位数来表示模型参数和梯度。传统的单精度浮点数使用 32 位表示,而 half precision 使用 16 位表示。虽然使用较少的位数会导致数值范围的缩小和精度的降低,但它能够显著减少模型计算的时间和内存需求,从而加快训练速度。许多现代的深度学习库和硬件加速器都支持 half precision 训练,使得在性能和资源之间取得了平衡。
本期内容编辑: Shawn
以上就是本期的 Hugging News,新的一周开始了,我们一起加油! 💪🎉