本文是 Compose 系列的第二篇文章。在 第一篇文章 中,我已经阐述了 Compose 的优点、Compose 所解决的问题、一些设计决策背后的原因,以及这些内容是如何帮助开发者的。此外,我还讨论了 Compose 的思维模型、您应如何考虑使用 Compose 编写代码,以及如何创建您自己的 API。
在本文中,我将着眼于 Compose 背后的工作原理。但在开始之前,我想要强调的是,使用 Compose 并不一定需要您理解它是如何实现的。接下来的内容纯粹是为了满足您的求知欲而撰写的。
@Composable 注解意味着什么?
如果您已经了解过 Compose,您大概已经在一些代码示例中看到过 @Composable 注解。这里有件很重要的事情需要注意—— Compose 并不是一个注解处理器。Compose 在 Kotlin 编译器的类型检测与代码生成阶段依赖 Kotlin 编译器插件工作,所以无需注解处理器即可使用 Compose。
这一注解更接近于一个语言关键字。作为类比,可以参考 Kotlin 的 suspend 关键 字:
// 函数声明
suspend fun MyFun() { … }
// lambda 声明
val myLambda = suspend { … }
// 函数类型
fun MyFun(myParam: suspend () -> Unit) { … }
Kotlin 的 suspend 关键字 适用于处理函数类型:您可以将函数、lambda 或者函数类型声明为 suspend。Compose 与其工作方式相同:它可以改变函数类型。
// 函数声明
@Composable fun MyFun() { … }
// lambda 声明
val myLambda = @Composable { … }
// 函数类型
fun MyFun(myParam: @Composable () -> Unit) { … }
这里的重点是,当您使用 @Composable 注解一个函数类型时,会导致它类型的改变:未被注解的相同函数类型与注解后的类型互不兼容。同样的,挂起 (suspend) 函数需要调用上下文作为参数,这意味着您只能在其他挂起函数中调用挂起函数:
fun Example(a: () -> Unit, b: suspend () -> Unit) {
a() // 允许
b() // 不允许
}
suspend
fun Example(a: () -> Unit, b: suspend () -> Unit) {
a() // 允许
b() // 允许
}
Composable 的工作方式与其相同。这是因为我们需要一个贯穿所有的上下文调用对象。
fun Example(a: () -> Unit, b: @Composable () -> Unit) {
a() // 允许
b() // 不允许
}
@Composable
fun Example(a: () -> Unit, b: @Composable () -> Unit) {
a() // 允许
b() // 允许
}
执行模式
所以,我们正在传递的调用上下文究竟是什么?还有,我们为什么需要传递它?
我们将其称之为 “Composer”。Composer 的实现包含了一个与 Gap Buffer (间隙缓冲区) 密切相关的数据结构,这一数据结构通常应用于文本编辑器。
间隙缓冲区是一个含有当前索引或游标的集合,它在内存中使用扁平数组 (flat array) 实现。这一扁平数组比它代表的数据集合要大,而那些没有使用的空间就被称为间隙。
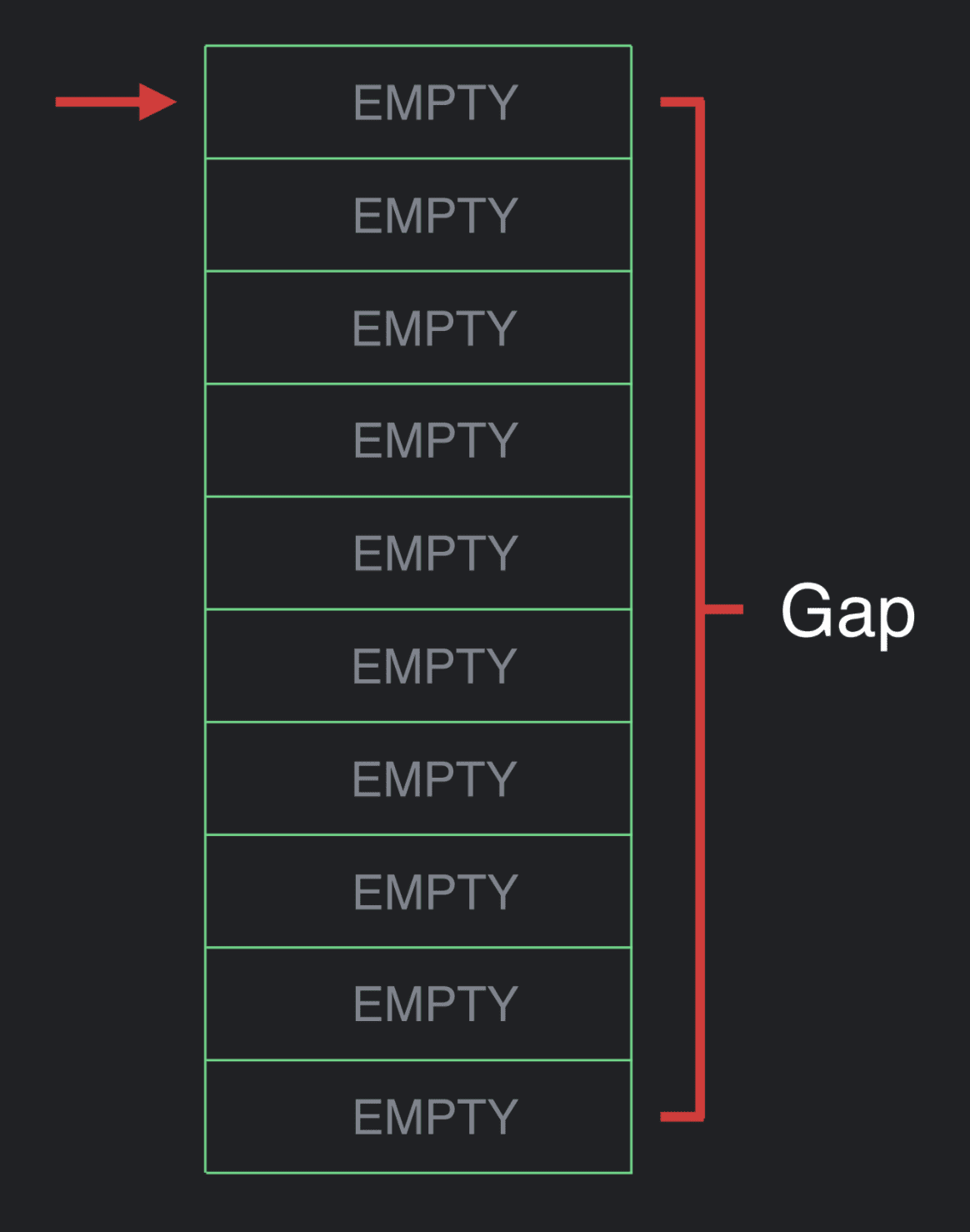
一个正在执行的 Composable 的层级结构可以使用这个数据结构,而且我们可以在其中插入一些东西。
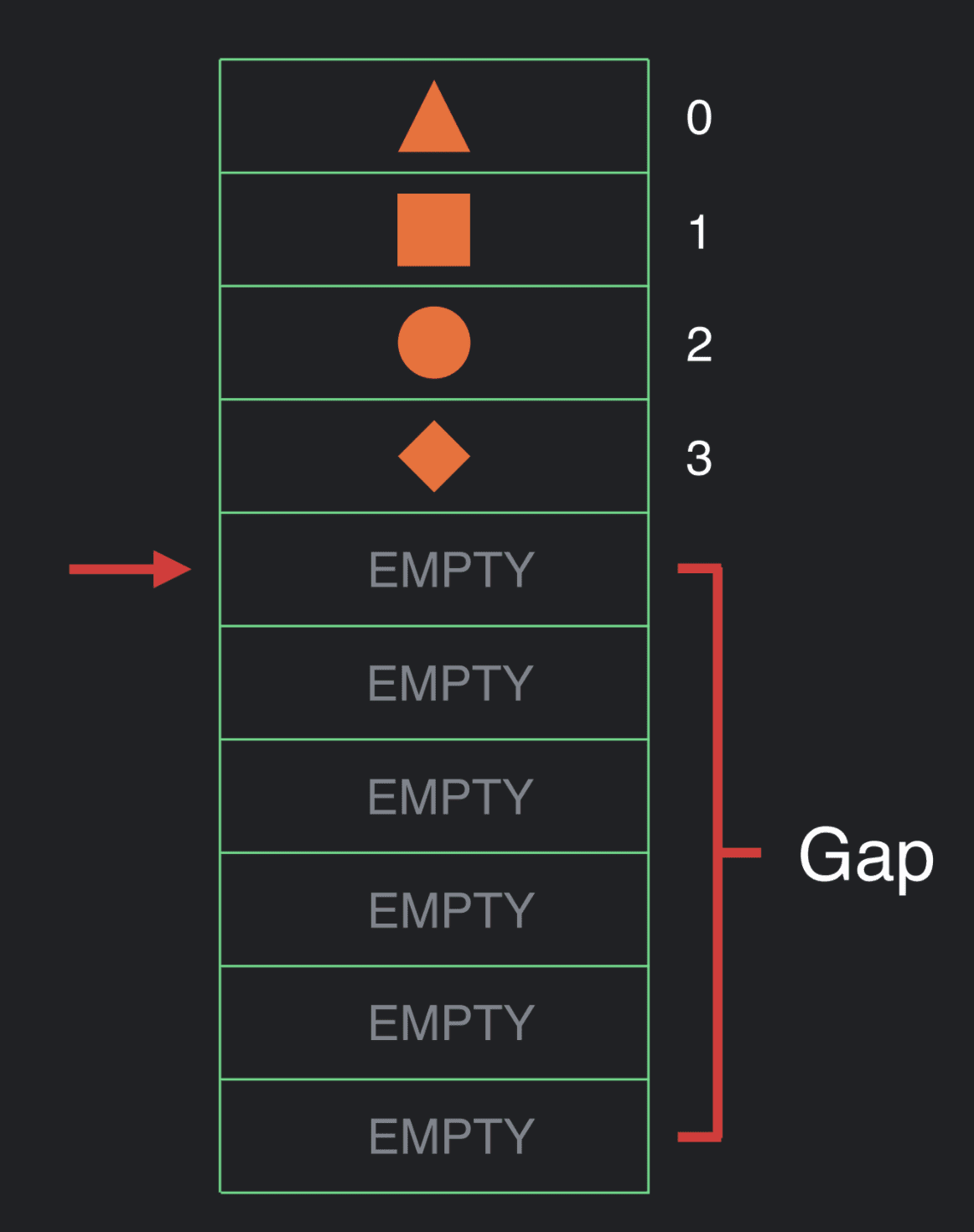
让我们假设已经完成了层级结构的执行。在某个时候,我们会重新组合一些东西。所以我们将游标重置回数组的顶部并再次遍历执行。在我们执行时,可以选择仅仅查看数据并且什么都不做,或是更新数据的值。
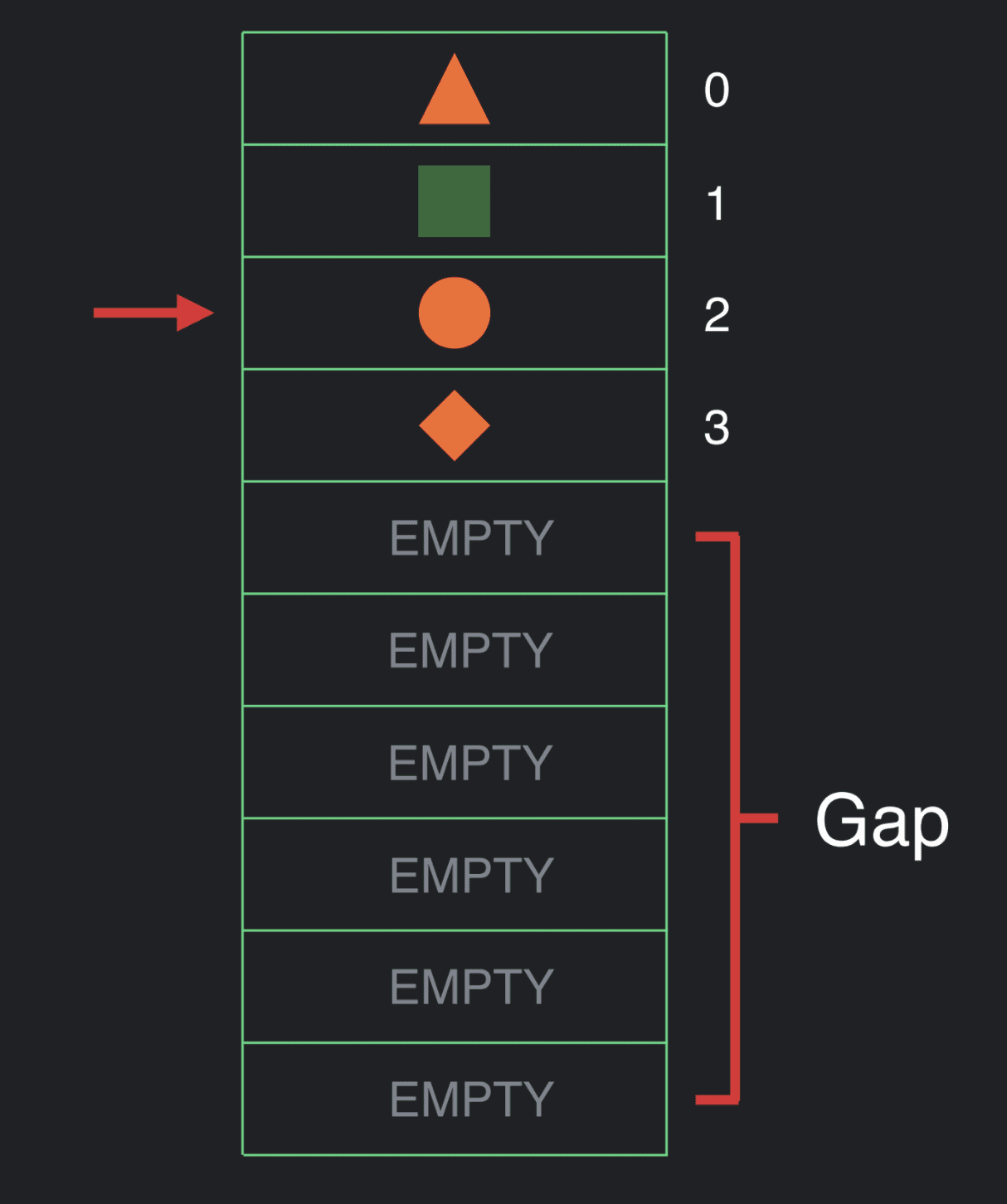
我们也许会决定改变 UI 的结构,并且希望进行一次插入操作。在这个时候,我们会把间隙移动至当前位置。
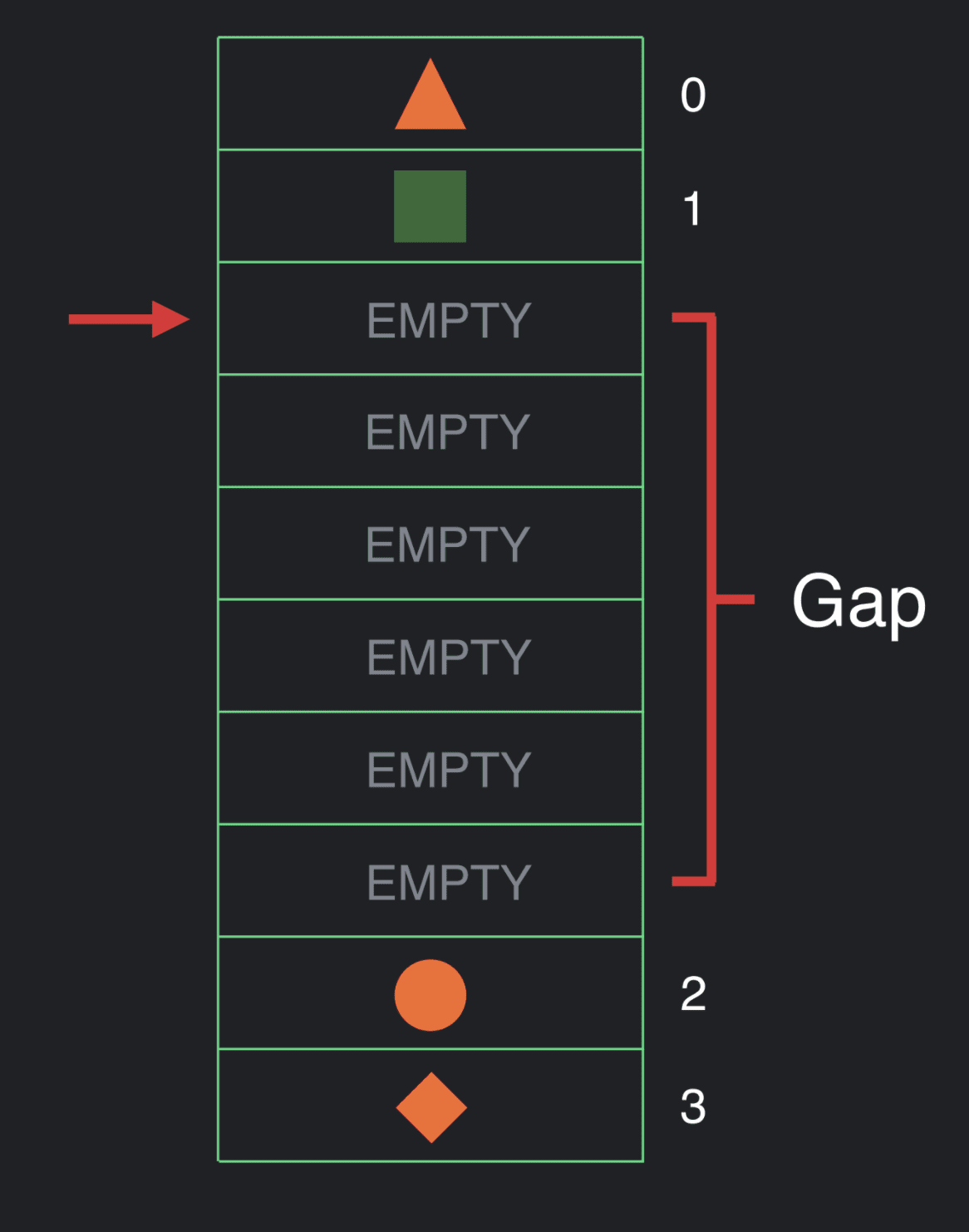
现在,我们可以进行插入操作了。
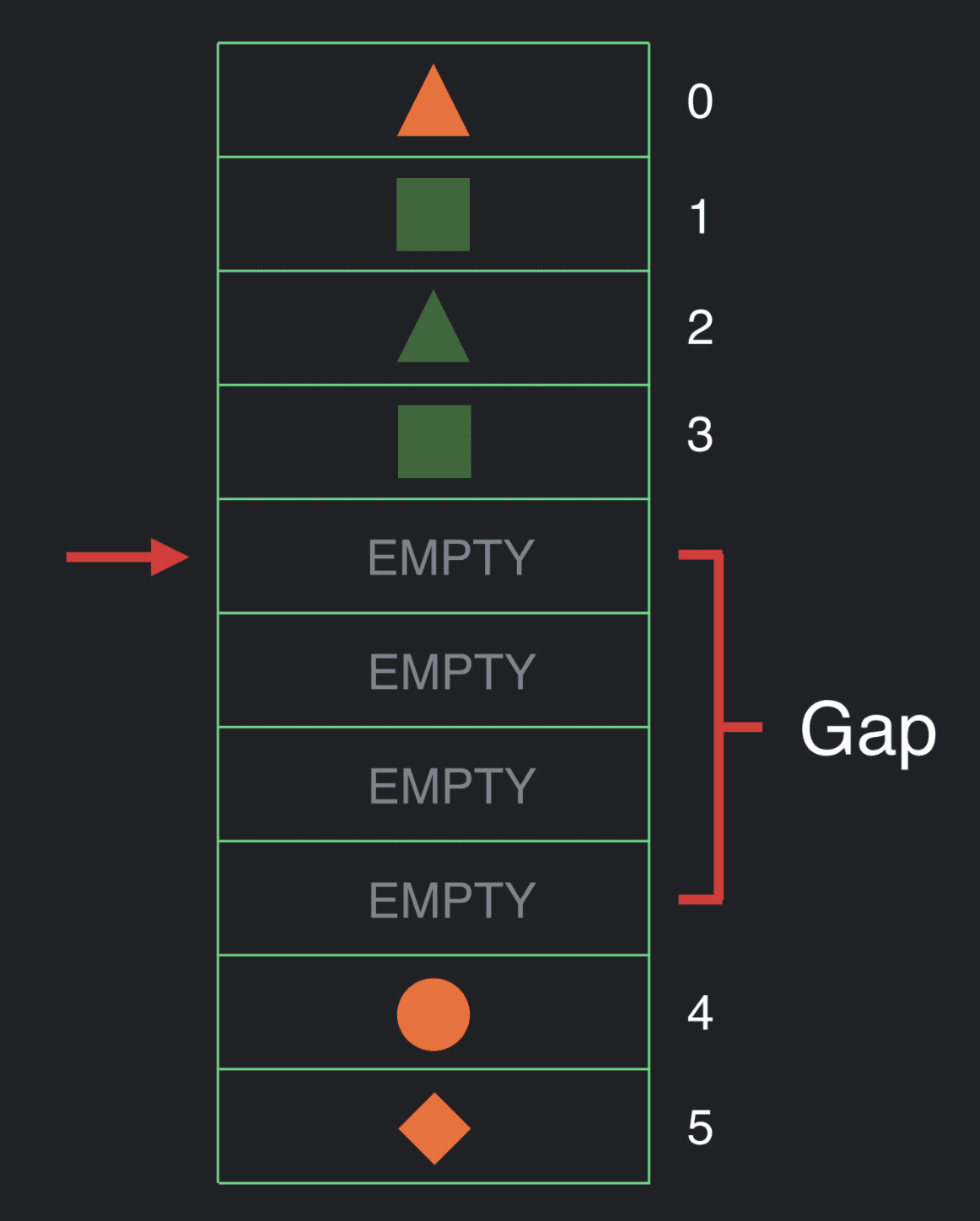
在了解此数据结构时,很重要的一点是除了移动间隙,它的所有其他操作包括获取 (get)、移动 (move) 、插入 (insert) 、删除 (delete) 都是常数时间操作。移动间隙的时间复杂度为 O(n)。我们选择这一数据结构是因为 UI 的结构通常不会频繁地改变。当我们处理动态 UI 时,它们的值虽然发生了改变,却通常不会频繁地改变结构。当它们确实需要改变结构时,则很可能需要做出大块的改动,此时进行 O(n) 的间隙移动操作便是一个很合理的权衡。
让我们来看一个计数器示例:
@Composable
fun Counter() {
var count by remember { mutableStateOf(0) }
Button(
text="Count: $count",
onPress={ count += 1 }
)
}
这是我们编写的代码,不过我们要看的是编译器做了什么。
当编译器看到 Composable 注解时,它会在函数体中插入额外的参数和调用。
首先,编译器会添加一个 composer.start 方法的调用,并向其传递一个编译时生成的整数 key。
fun Counter($composer: Composer) {
$composer.start(123)
var count by remember { mutableStateOf(0) }
Button(
text="Count: $count",
onPress={ count += 1 }
)
$composer.end()
}
编译器也会将 composer 对象传递到函数体里的所有 composable 调用中。
fun Counter($composer: Composer) {
$composer.start(123)
var count by remember($composer) { mutableStateOf(0) }
Button(
$composer,
text="Count: $count",
onPress={ count += 1 },
)
$composer.end()
}
当此 composer 执行时,它会进行以下操作:
- Composer.start 被调用并存储了一个组对象 (group object)
- remember 插入了一个组对象
- mutableStateOf 的值被返回,而 state 实例会被存储起来
- Button 基于它的每个参数存储了一个分组
最后,当我们到达 composer.end 时:

数据结构现在已经持有了来自组合的所有对象,整个树的节点也已经按照深度优先遍历的执行顺序排列。
现在,所有这些组对象已经占据了很多的空间,它们为什么要占据这些空间呢?这些组对象是用来管理动态 UI 可能发生的移动和插入的。编译器知道哪些代码会改变 UI 的结构,所以它可以有条件地插入这些分组。大部分情况下,编译器不需要它们,所以它不会向插槽表 (slot table) 中插入过多的分组。为了说明一这点,请您查看以下条件逻辑:
@Composable fun App() {
val result = getData()
if (result == null) {
Loading(...)
} else {
Header(result)
Body(result)
}
}
在这个 Composable 函数中,getData 函数返回了一些结果并在某个情况下绘制了一个 Loading composable 函数;而在另一个情况下,它绘制了 Header 和 Body 函数。编译器会在 if 语句的每个分支间插入分隔关键字。
fun App($composer: Composer) {
val result = getData()
if (result == null) {
$composer.start(123)
Loading(...)
$composer.end()
} else {
$composer.start(456)
Header(result)
Body(result)
$composer.end()
}
}
让我们假设这段代码第一次执行的结果是 null。这会使一个分组插入空隙并运行载入界面。
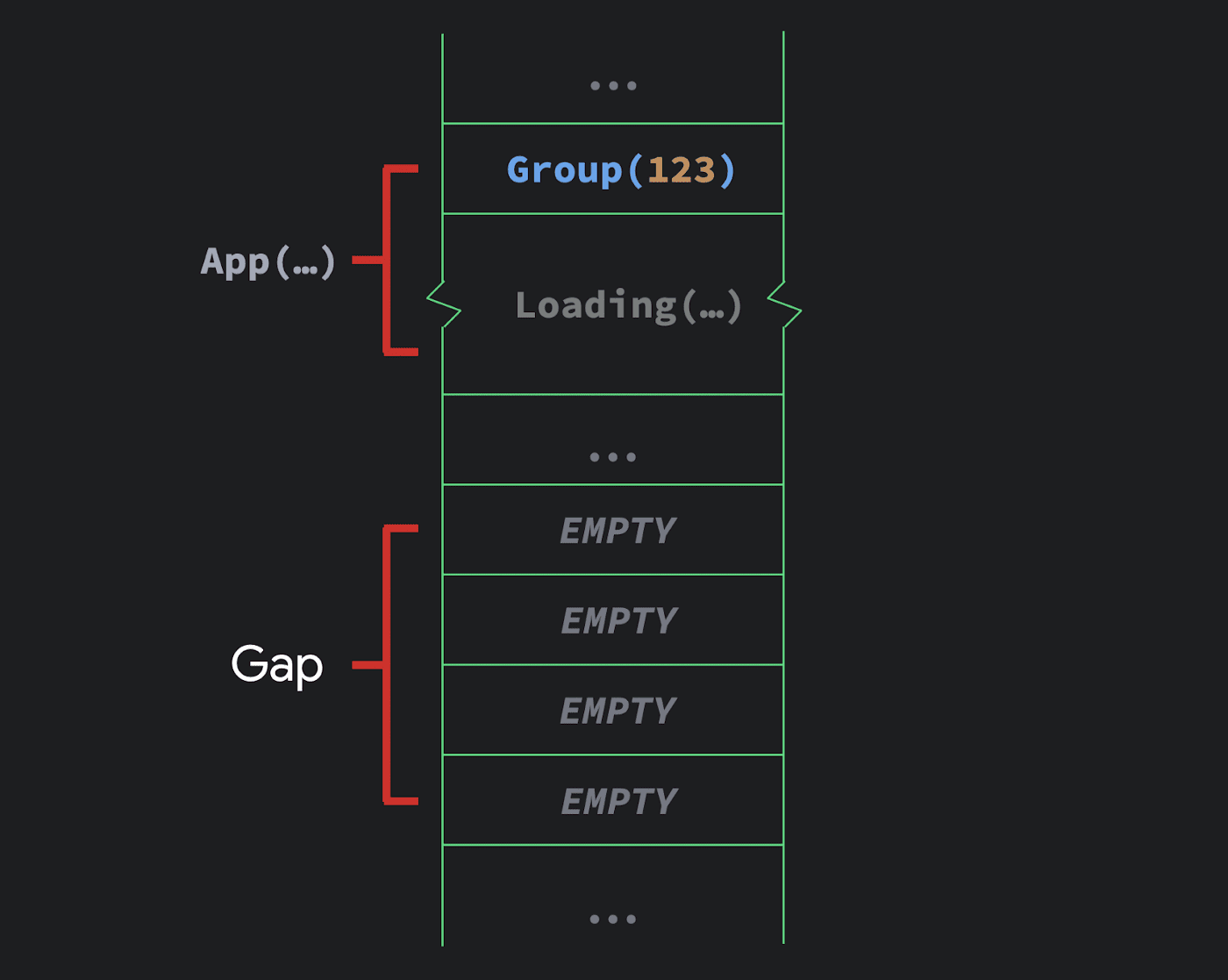
函数第二次执行时,让我们假设它的结果不再是 null,这样一来第二个分支就会执行。这里便是它变得有趣的地方。
对 composer.start 的调用有一个 key 为 456 的分组。编译器会看到插槽表中 key 为 123 分组与之并不匹配,所以此时它知道 UI 的结构发生了改变。
于是编译器将缝隙移动至当前游标位置并使其在以前 UI 的位置进行扩展,从而有效地消除了旧的 UI。
此时,代码已经会像一般的情况一样执行,而且新的 UI —— header 和 body —— 也已被插入其中。
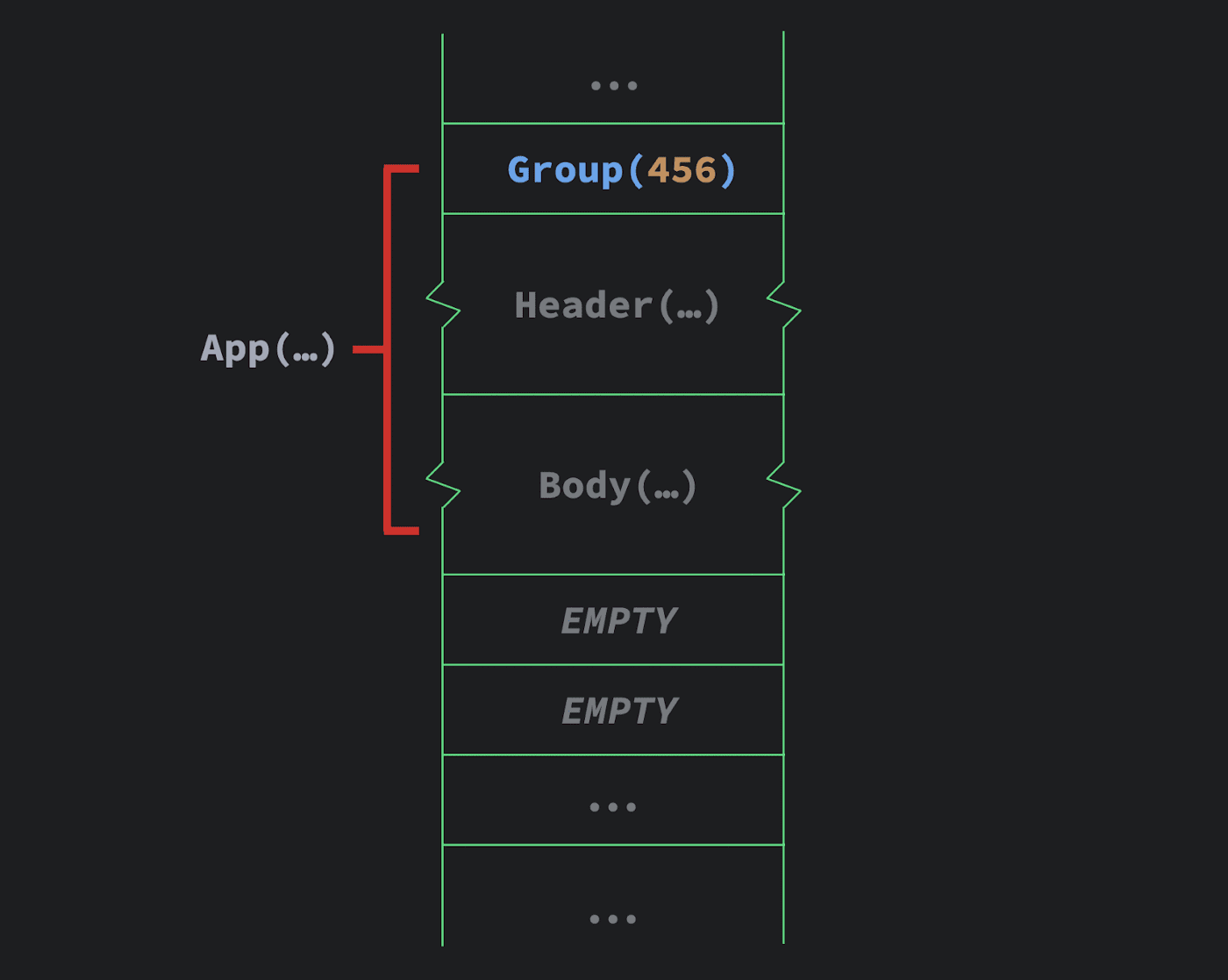
在这种情况下,if 语句的开销为插槽表中的单个条目。通过插入单个组,我们可以在 UI 中任意实现控制流,同时启用编译器对 UI 的管理,使其可以在处理 UI 时利用这种类缓存的数据结构。
这是一种我们称之为 Positional Memoization 的概念,同时也是自创建伊始便贯穿整个 Compose 的概念。
Positional Memoization (位置记忆化)
通常,我们所说的全局记忆化,指的是编译器基于函数的输入缓存了其结果。下面是一个正在执行计算的函数,我们用它作为位置记忆化的示例:
@Composable
fun App(items: List<String>, query: String) {
val results = items.filter { it.matches(query) }
// ...
}
该函数接收一个字符串列表与一个要查找的字符串,并在接下来对列表进行了过滤计算。我们可以将该计算包装至对 remember 函数的调用中——remember 函数知道如何利用插槽列表。remember 函数会查看列表中的字符串,同时也会存储列表并在插槽表中对其进行查询。过滤计算会在之后运行,并且 remember 函数会在结果传回之前对其进行存储。
函数第二次执行时,remember 函数会查看新传入的值并将其与旧值进行对比,如果所有的值都没有发生改变,过滤操作就会在跳过的同时将之前的结果返回。这便是位置记忆化。
有趣的是,这一操作的开销十分低廉:编译器必须存储一个先前的调用。这一计算可以发生在您的 UI 的各个地方,由于您是基于位置对其进行存储,因此只会为该位置进行存储。
下面是 remember 的函数签名,它可以接收任意多的输入与一个 calculation 函数。
@Composable
fun <T> remember(vararg inputs: Any?, calculation: () -> T): T
不过,这里没有输入时会产生一个有趣的退化情况。我们可以故意误用这一 API,比如记忆一个像 Math.random 这样不输出稳定结果的计算:
@Composable fun App() {
val x = remember { Math.random() }
// ...
}
使用全局记忆化来进行这一操作将不会有任何意义,但如果换做使用位置记忆化,此操作将最终呈现出一种新的语义。每当我们在 Composable 层级中使用 App 函数时,都将会返回一个新的 Math.random 值。不过,每次 Composable 被重新组合时,它将会返回相同的 Math.random 值。这一特性使得持久化成为可能,而持久化又使得状态成为可能。
存储参数
下面,让我们用 Google Composable 函数来说明 Composable 是如何存储函数的参数的。这个函数接收一个数字作为参数,并且通过调用 Address Composable 函数来绘制地址。
@Composable fun Google(number: Int) {
Address(
number=number,
street="Amphitheatre Pkwy",
city="Mountain View",
state="CA"
zip="94043"
)
}
@Composable fun Address(
number: Int,
street: String,
city: String,
state: String,
zip: String
) {
Text("$number $street")
Text(city)
Text(", ")
Text(state)
Text(" ")
Text(zip)
}
Compose 将 Composable 函数的参数存储在插槽表中。在本例中,我们可以看到一些冗余:Address 调用中添加的 “Mountain View” 与 “CA” 会在下面的文本调用被再次存储,所以这些字符串会被存储两次。
我们可以在编译器级为 Composable 函数添加 static 参数来消除这种冗余。
fun Google(
$composer: Composer,
$static: Int,
number: Int
) {
Address(
$composer,
0b11110 or ($static and 0b1),
number=number,
street="Amphitheatre Pkwy",
city="Mountain View",
state="CA"
zip="94043"
)
}
本例中,static 参数是一个用于指示运行时是否知道参数不会改变的位字段。如果已知一个参数不会改变,则无需存储该参数。所以这一 Google 函数示例中,编译器传递了一个位字段来表示所有参数都不会发生改变。
接下来,在 Address 函数中,编译器可以执行相同的操作并将参数传递给 text。
fun Address(
$composer: Composer,
$static: Int,
number: Int, street: String,
city: String, state: String, zip: String
) {
Text($composer, ($static and 0b11) and (($static and 0b10) shr 1), "$number $street")
Text($composer, ($static and 0b100) shr 2, city)
Text($composer, 0b1, ", ")
Text($composer, ($static and 0b1000) shr 3, state)
Text($composer, 0b1, " ")
Text($composer, ($static and 0b10000) shr 4, zip)
}
这些位操作逻辑难以阅读且令人困惑,但我们也没有必要理解它们:编译器擅长于此,而人类则不然。
在 Google 函数的实例中,我们看到这里不仅有冗余,而且有一些常量。事实证明,我们也不需要存储它们。这样一来,number 参数便可以决定整个层级,它也是唯一一个需要编译器进行存储的值。
有赖于此,我们可以更进一步,生成可以理解 number 是唯一一个会发生改变的值的代码。接下来这段代码可以在 number 没有发生改变时直接跳过整个函数体,而我们也可以指导 Composer 将当前索引移动至函数已经执行到的位置。
fun Google(
$composer: Composer,
number: Int
) {
if (number == $composer.next()) {
Address(
$composer,
number=number,
street="Amphitheatre Pkwy",
city="Mountain View",
state="CA"
zip="94043"
)
} else {
$composer.skip()
}
}
Composer 知道快进至需要恢复的位置的距离。
重组
为了解释重组是如何工作的,我们需要回到计数器的例子:
fun Counter($composer: Composer) {
$composer.start(123)
var count = remember($composer) { mutableStateOf(0) }
Button(
$composer,
text="Count: ${count.value}",
onPress={ count.value += 1 },
)
$composer.end()
}
编译器为 Counter 函数生成的代码含有一个 composer.start 和一个 compose.end。每当 Counter 执行时,运行时就会理解:当它调用 count.value 时,它会读取一个 appmodel 实例的属性。在运行时,每当我们调用 compose.end,我们都可以选择返回一个值。
$composer.end()?.updateScope { nextComposer ->
Counter(nextComposer)
}
接下来,我们可以在该返回值上使用 lambda 来调用 updateScope 方法,从而告诉运行时在有需要时如何重启当前的 Composable。这一方法等同于 LiveData 接收的 lambda 参数。在这里使用问号的原因——可空的原因——是因为如果我们在执行 Counter 的过程中不读取任何模型对象,则没有理由告诉运行时如何更新它,因为我们知道它永远不会更新。
最后
您一定要记得的重要一点是,这些细节中的绝大部分只是实现细节。与标准的 Kotlin 函数相比, Composable 函数具有不同的行为和功能。有时候理解如何实现十分有用,但是未来 Composable 函数的行为与功能不会改变,而实现则有可能发生变化。
同样的,Compose 编译器在某些状况下可以生成更为高效的代码。随着时间流逝,我们也期待优化这些改进。