注意 : 本文同时也是 Transformers 的文档。
以 GPT3/4、Falcon 以及 LLama 为代表的大语言模型 (Large Language Model,LLM) 在处理以人为中心的任务上能力突飞猛进,俨然已成为现代知识型行业的重要工具。
然而,在实际部署这些模型时,我们仍面临不少挑战:
- 为了展现可媲美人类的文本理解和生成能力,LLM 的参数量一般需要达到数十亿 (参见 Kaplan 等人、Wei 等人 的论述),随之而来的是对推理内存的巨大需求。
- 在许多实际任务中,LLM 需要广泛的上下文信息,这就要求模型在推理过程中能够处理很长的输入序列。
这些挑战的关键在于增强 LLM 的计算和存储效能,特别是如何增强长输入序列的计算和存储效能。
本文,我们将回顾迄今为止那些最有效的技术,以应对高效 LLM 部署的挑战:
- 低精度: 研究表明,低精度 (即 8 比特和 4 比特) 推理可提高计算效率,且对模型性能没有显著影响。
- Flash 注意力: Flash 注意力是注意力算法的一个变种,它不仅更节省内存,而且通过优化 GPU 内存利用率从而提升了计算效率。
- 架构创新: 考虑到 LLM 推理的部署方式始终为: 输入序列为长文本的自回归文本生成,因此业界提出了专门的模型架构,以实现更高效的推理。这方面最重要的进展有 Alibi、旋转式嵌入 (rotary embeddings) 、多查询注意力 (Multi-Query Attention,MQA) 以及 分组查询注意 (Grouped Query Attention,GQA) 。
本文,我们将从张量的角度对自回归生成进行分析。我们深入研究了低精度的利弊,对最新的注意力算法进行了全面的探索,并讨论了改进的 LLM 架构。在此过程中,我们用实际的例子来展示每项技术所带来的改进。
1. 充分利用低精度的力量
通过将 LLM 视为一组权重矩阵及权重向量,并将文本输入视为向量序列,可以更好地理解 LLM 的内存需求。下面, 权重 表示模型的所有权重矩阵及向量。
迄今为止,一个 LLM 至少有数十亿参数。每个参数均为十进制数,例如 4.5689 通常存储成 float32、bfloat16 或 float16 格式。因此,我们能够轻松算出加载 LLM 所需的内存:
加载 X B 参数的 FP32 模型权重需要大约 4 * X GB 显存
现如今,很少有模型以 float32 精度进行训练,通常都是以 bfloat16 精度训练的,在很少情况下还会以 float16 精度训练。因此速算公式就变成了:
加载有 X B 参数的 BF16/FP16 模型权重需要大约 2 * X GB 显存
对于较短的文本输入 (词元数小于 1024),推理的内存需求很大程度上取决于模型权重的大小。因此,现在我们假设推理的内存需求等于将模型加载到 GPU 中所需的显存量。
我们举几个例子来说明用 bfloat16 加载模型大约需要多少显存:
- GPT3 需要 2 * 175 GB = 350 GB 显存
- Bloom 需要 2 * 176 GB = 352 GB 显存
- Llama-2-70b 需要 2 * 70 GB = 140 GB 显存
- Falcon-40b 需要 2 * 40 GB = 80 GB 显存
- MPT-30b 需要 2 * 30 GB = 60 GB 显存
- bigcode/starcoder 需要 2 * 15.5 = 31 GB 显存
迄今为止,市面上显存最大的 GPU 芯片是 80GB 显存的 A100。前面列出的大多数模型需要超过 80GB 才能加载,因此必然需要 张量并行 和/或 流水线并行。
![]() Transformers 不支持开箱即用的张量并行,因为它需要特定的模型架构编写方式。如果你对以张量并行友好的方式编写模型感兴趣,可随时查看 TGI(text generation inference) 库。
Transformers 不支持开箱即用的张量并行,因为它需要特定的模型架构编写方式。如果你对以张量并行友好的方式编写模型感兴趣,可随时查看 TGI(text generation inference) 库。
![]() Transformers 开箱即用地支持简单的流水线并行。为此,只需使用
Transformers 开箱即用地支持简单的流水线并行。为此,只需使用 device="auto" 加载模型,它会自动将不同层放到相应的 GPU 上,详见 此处。
但请注意,虽然非常有效,但这种简单的流水线并行并不能解决 GPU 空闲的问题。可参考 此处 了解更高级的流水线并行技术。
如果你能访问 8 x 80GB A100 节点,你可以按如下方式加载 BLOOM:
!pip install transformers accelerate bitsandbytes optimum
# from transformers import AutoModelForCausalLM
# model = AutoModelForCausalLM.from_pretrained("bigscience/bloom", device_map="auto", pad_token_id=0)
通过使用 device_map="auto" ,注意力层将均匀分布在所有可用的 GPU 上。
本文,我们选用 bigcode/octocoder 模型,因为它可以在单个 40GB A100 GPU 上运行。请注意,下文所有的内存和速度优化同样适用于需要模型或张量并行的模型。
由于我们以 bfloat16 精度加载模型,根据上面的速算公式,预计使用 “bigcode/octocoder” 运行推理所需的显存约为 31 GB。我们试试吧!
首先加载模型和分词器,并将两者传递给 Transformers 的 pipeline。
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto", pad_token_id=0)
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
prompt = "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer:"
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
输出:
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
好,现在我们可以把生成的函数直接用于将字节数转换为千兆字节数。
def bytes_to_giga_bytes(bytes):
return bytes / 1024 / 1024 / 1024
我们直接调用 torch.cuda.max_memory_allocated 来测量 GPU 显存的峰值占用。
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
输出:
29.0260648727417
相当接近我们的速算结果!我们可以看到这个数字并不完全准确,因为从字节到千字节需要乘以 1024 而不是 1000。因此,速算公式也可以理解为“最多 X GB”。
请注意,如果我们尝试以全 float32 精度运行模型,则需要高达 64GB 的显存。
现在几乎所有模型都是用 bfloat16 中训练的,如果 你的 GPU 支持 bfloat16 的话,你就不应该以 float32 来运行推理。float32 并不会提供比训练精度更好的推理结果。
如果你不确定 Hub 上的模型权重的精度如何,可随时查看模型配置文件内的 torch_dtype 项, 如 此处。建议在使用 from_pretrained(..., torch_dtype=...) 加载模型时将精度设置为与配置文件中的精度相同,该接口的默认精度为 float32。这样的话,你就可以使用 float16 或 bfloat16 来推理了。
我们再定义一个 flush(...) 函数来释放所有已分配的显存,以便我们可以准确测量分配的 GPU 显存的峰值。
del pipe
del model
import gc
import torch
def flush():
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
下一个实验我们就可以调用它了。
flush()
在最新的 accelerate 库中,你还可以使用名为 release_memory() 的方法。
from accelerate.utils import release_memory
# ...
release_memory(model)
那如果你的 GPU 没有 32GB 显存怎么办?研究发现,模型权重可以量化为 8 比特或 4 比特,而对模型输出没有明显影响 (参见 Dettmers 等人的论文)。
甚至可以将模型量化为 3 或 2 比特,对输出的影响仍可接受,如最近的 GPTQ 论文 ![]() 所示。
所示。
总的来讲,量化方案旨在降低权重的精度,同时尽量保持模型的推理结果尽可能准确 ( 即 尽可能接近 bfloat16)。
请注意,量化对于文本生成特别有效,因为我们关心的是选择 最可能的下一个词元的分布 ,而不真正关心下一个词元的确切 logit 值。所以,只要下一个词元 logit 大小顺序保持相同, argmax 或 topk 操作的结果就会相同。
量化技术有很多,我们在这里不作详细讨论,但一般来说,所有量化技术的工作原理如下:
- 将所有权重量化至目标精度
- 加载量化权重,并把
bfloat16精度的输入向量序列传给模型 - 将权重动态反量化为
bfloat16,并基于bfloat16精度与输入进行计算 - 计算后,将权重再次量化回目标精度。[译者注: 这一步一般不需要做]
简而言之,这意味着原来的每个 输入数据 - 权重矩阵乘 ,其中 X 为 输入 , W 为权重矩阵,Y 为输出:
$$ Y = X \times W $$
都变成了:
$$ Y = X \times \text{dequantize}(W); \text{quantize}(W) $$
当输入向量走过模型计算图时,所有权重矩阵都会依次执行反量化和重量化操作。
因此,使用权重量化时,推理时间通常 不会 减少,反而会增加。
到此为止理论讲完了,我们可以开始试试了!要使用 Transformer 权重量化方案,请确保
bitsandbytes 库已安装。
# !pip install bitsandbytes
然后,只需在 from_pretrained 中添加 load_in_8bit=True 参数,即可用 8 比特量化加载模型。
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True, pad_token_id=0)
现在,再次运行我们的示例,并测量其显存使用情况。
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
输出:
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
很好,我们得到了与之前一样的结果,这就说明准确性没有损失!我们看一下这次用了多少显存。
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
输出:
15.219234466552734
显存明显减少!降至 15GB 多一点,这样就可以在 4090 这样的消费级 GPU 上运行该模型了。
我们看到内存效率有了很大的提高,且模型的输出没啥退化。同时,我们也注意到推理速度出现了轻微的减慢。
删除模型并再次刷一下显存。
del model
del pipe
flush()
然后,我们看下 4 比特量化的 GPU 显存消耗峰值是多少。可以用与之前相同的 API 将模型量化为 4 比特 - 这次参数设置为 load_in_4bit=True 而不是 load_in_8bit=True 。
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True, low_cpu_mem_usage=True, pad_token_id=0)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result
输出:
Here is a Python function that transforms bytes to Giga bytes:\n\n```\ndef bytes_to_gigabytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single argument
输出几乎与以前相同 - 只是在代码片段之前缺了 python 这个词。我们看下需要多少显存。
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
输出:
9.543574333190918
仅需 9.5GB!对于参数量大于 150 亿的模型来说,确实不算多。
虽然我们这里看到模型的准确性几乎没有下降,但与 8 比特量化或完整的 bfloat16 推理相比,4 比特量化实际上通常会导致不同的结果。到底用不用它,就看用户自己抉择了。
另请注意,与 8 比特量化相比,其推理速度会更慢一些,这是由于 4 比特量化使用了更激进的量化方法,导致 \text{quantize} 和 \text {dequantize} 在推理过程中花的时间更长。
del model
del pipe
flush()
总的来说,我们发现以 8 比特精度运行 OctoCoder 将所需的 GPU 显存 从 32GB 减少到仅 15GB,而以 4 比特精度运行模型则进一步将所需的 GPU 显存减少到 9GB 多一点。
4 比特量化让模型可以在 RTX3090、V100 和 T4 等大多数人都可以轻松获取的 GPU 上运行。
更多有关量化的信息以及有关如何量化模型以使其显存占用比 4 比特更少,我们建议大家查看 AutoGPTQ 的实现。
总结一下,重要的是要记住,模型量化会提高内存效率,但会牺牲准确性,在某些情况下还会牺牲推理时间。
如果 GPU 显存对你而言不是问题,通常不需要考虑量化。然而,如果不量化,许多 GPU 根本无法运行 LLM,在这种情况下,4 比特和 8 比特量化方案是非常有用的工具。
更详细的使用信息,我们强烈建议你查看 Transformers 的量化文档。
接下来,我们看看如何用更好的算法和改进的模型架构来提高计算和内存效率。
2. Flash 注意力: 速度飞跃
当今表现最好的 LLM 其基本架构大体相似,包括前馈层、激活层、层归一化层以及最重要的自注意力层。
自注意力层是大语言模型 (LLM) 的核心,因为其使模型能够理解输入词元之间的上下文关系。然而,自注意力层在计算以及峰值显存这两个方面都随着输入词元的数目 (也称为 序列长度 ,下文用 N 表示) 呈 二次方 增长。
虽然这对于较短的输入序列 (输入词元数小于 1000) 来说并不明显,但对于较长的输入序列 (如: 约 16000 个输入词元) 来说,就会成为一个严重的问题。
我们仔细分析一下。计算长度为 N 的输入序列 \mathbf{X} 的自注意力层的输出 \mathbf{O} ,其公式为:
$$ \textbf{O} = \text{Attn}(\mathbf{X}) = \mathbf{V} \times \text{Softmax}(\mathbf{QK}^T) \text{ ,其中 } \mathbf{Q} = \mathbf{W}_q \mathbf{X}, \mathbf{V} = \mathbf{W}_v \mathbf{X}, \mathbf{K} = \mathbf{W}_k \mathbf{X} $$
\mathbf{X} = (\mathbf{x} _1, … \mathbf{x}_ {N}) 是注意力层的输入序列。投影 \mathbf{Q} 和 \mathbf{K} 也是 N 个向量组成的序列,其乘积 \mathbf{QK}^T 的大小为 N^2 。
LLM 通常有多个注意力头,因此可以并行进行多个自注意力计算。
假设 LLM 有 40 个注意力头并以 bfloat16 精度运行,我们可以计算出存储 \mathbf{QK^T} 矩阵的内存需求为 40 \times 2 \times N^2 字节。当 N=1000 时仅需要大约 50MB 的显存,但当 N=16000 时,我们需要 19GB 的显存,当 N=100,000 时,仅存储 \mathbf{QK}^T 矩阵就需要近 1TB。
总之,随着输入上下文越来越长,默认的自注意力算法所需的内存很快就会变得非常昂贵。
伴随着 LLM 在文本理解和生成方面的进展,它们正被应用于日益复杂的任务。之前,我们主要用模型来对几个句子进行翻译或摘要,但现在我们会用这些模型来管理整页的文本,这就要求它们具有处理长输入文本的能力。
我们如何摆脱长输入文本对内存的过高要求?我们需要一种新的方法让我们在计算自注意力机制时能够摆脱 QK^T 矩阵。 Tri Dao 等人 开发了这样一种新算法,并将其称为 Flash 注意力。
简而言之,Flash 注意力将 \mathbf{V} \times \text{Softmax}(\mathbf{QK}^T) 的计算分解成若干步骤,通过迭代多个 softmax 计算步来将输出分成多个较小的块进行计算:
$$ \textbf{O} i \leftarrow s^a {ij} \times \textbf{O} i + s^b {ij} \times \mathbf{V} {j} \times \text{Softmax}(\mathbf{QK}^T {i,j}) \text{,在 } i, j \text{ 上迭代} $$
其中 s^a_{ij} 和 s^b_{ij} 是随着每个 i 和 j 迭代更新的 softmax 统计归一化值。
请注意,整个 Flash 注意力有点复杂,这里已经大大简化了。如果想要深入理解,可以阅读 Flash Attention 的论文。
要点如下:
通过跟踪 softmax 统计归一化值再加上一些聪明的数学技巧,与默认的自注意力层相比,Flash 注意力的计算结果 完全相同,而内存成本仅随着 N 线性增加。
仅看这个公式,直觉上来讲,Flash 注意力肯定比默认的自注意力公式要慢很多,因为需要进行更多的计算。确实,与普通注意力相比,Flash 注意力需要更多的 FLOP,因为需要不断重新计算 softmax 统计归一化值 (如果感兴趣,请参阅 论文 以了解更多详细信息)。
然而,与默认注意力相比,Flash 注意力的推理速度要快得多,这是因为它能够显著减少对较慢的高带宽显存的需求,而更多使用了更快的片上内存 (SRAM)。
从本质上讲,Flash 注意力确保所有中间写入和读取操作都可以使用快速 片上 SRAM 来完成,而不必访问较慢的显存来计算输出向量 \mathbf{O}。
实际上,如果能用的话,我们没有理由不用 Flash 注意力。该算法在数学上给出相同的输出,但速度更快且内存效率更高。
我们看一个实际的例子。
我们的 OctoCoder 模型现在被输入了长得多的提示,其中包括所谓的“系统提示”。系统提示用于引导 LLM 去适应特定的用户任务。
接下来,我们使用系统提示,引导 OctoCoder 成为更好的编程助手。
system_prompt = """Below are a series of dialogues between various people and an AI technical assistant.
The assistant tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble but knowledgeable.
The assistant is happy to help with code questions and will do their best to understand exactly what is needed.
It also tries to avoid giving false or misleading information, and it caveats when it isn't entirely sure about the right answer.
That said, the assistant is practical really does its best, and doesn't let caution get too much in the way of being useful.
The Starcoder models are a series of 15.5B parameter models trained on 80+ programming languages from The Stack (v1.2) (excluding opt-out requests).
The model uses Multi Query Attention, was trained using the Fill-in-the-Middle objective, and with 8,192 tokens context window for a trillion tokens of heavily deduplicated data.
-----
Question: Write a function that takes two lists and returns a list that has alternating elements from each input list.
Answer: Sure. Here is a function that does that.
def alternating(list1, list2):
results = []
for i in range(len(list1)):
results.append(list1[i])
results.append(list2[i])
return results
Question: Can you write some test cases for this function?
Answer: Sure, here are some tests.
assert alternating([10, 20, 30], [1, 2, 3]) == [10, 1, 20, 2, 30, 3]
assert alternating([True, False], [4, 5]) == [True, 4, False, 5]
assert alternating([], []) == []
Question: Modify the function so that it returns all input elements when the lists have uneven length. The elements from the longer list should be at the end.
Answer: Here is the modified function.
def alternating(list1, list2):
results = []
for i in range(min(len(list1), len(list2))):
results.append(list1[i])
results.append(list2[i])
if len(list1) > len(list2):
results.extend(list1[i+1:])
else:
results.extend(list2[i+1:])
return results
-----
"""
为了演示需要,我们将系统提示复制十倍,以便输入长度足够长以观察 Flash 注意力带来的内存节省。然后在其后加上原始提示 "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here" :
long_prompt = 10 * system_prompt + prompt
以 bfloat16 精度再次初始化模型。
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
现在,我们可以像以前一样运行模型,同时测量其峰值 GPU 显存需求及推理时间。
import time
start_time = time.time()
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
result
输出:
Generated in 10.96854019165039 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
输出与之前一样,但是这一次,模型会多次重复答案,直到达到 60 个词元为止。这并不奇怪,因为出于演示目的,我们将系统提示重复了十次,从而提示模型重复自身。
注意,在实际应用中,系统提示不应重复十次 —— 一次就够了!
我们测量一下峰值 GPU 显存需求。
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
输出:
37.668193340301514
正如我们所看到的,峰值 GPU 显存需求现在明显高于以前,这主要是因为输入序列变长了。整个生成过程也需要一分多钟的时间。
我们调用 flush() 来释放 GPU 内存以供下一个实验使用。
flush()
为便于比较,我们运行相同的函数,但启用 Flash 注意力。
为此,我们将模型转换为 BetterTransformers,这会因此而启用 PyTorch 的 SDPA 自注意力,其实现是基于 Flash 注意力的。
model.to_bettertransformer()
现在我们运行与之前完全相同的代码片段,但此时 Transformers 在底层将使用 Flash 注意力。
start_time = time.time()
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
result
输出:
Generated in 3.0211617946624756 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
结果与之前完全相同,但由于 Flash 注意力,我们可以观察到非常显著的加速。
我们最后一次测量一下内存消耗。
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
输出:
32.617331981658936
我们几乎一下就回到了原来的 29GB 峰值 GPU 显存。
我们可以观察到,与刚开始的短输入序列相比,使用 Flash 注意力且输入长序列时,我们只多用了大约 100MB 的 GPU 显存。
flush()
3. 架构背后的科学: 长文本输入和聊天式 LLM 的策略选择
到目前为止,我们已经研究了通过以下方式提高计算和内存效率:
- 将权重转换为较低精度的格式
- 用内存和计算效率更高的版本替换自注意力算法
现在让我们看看如何改变 LLM 的架构,使其对于需要长文本输入的任务更高效, 例如 :
- 检索增强问答
- 总结
- 聊天
请注意, 聊天 应用不仅需要 LLM 处理长文本输入,还需要 LLM 能够有效地处理用户和助手之间的多轮对话 (例如 ChatGPT)。
一旦经过训练,LLM 的基本架构就很难改变,因此提前考虑 LLM 的任务特征并相应地优化模型架构非常重要。模型架构中有两个重要组件很快就会成为长输入序列的内存和/或性能瓶颈。
- 位置嵌入 (positional embeddings)
- 键值缓存 (key-value cache)
我们来一一详细探讨:
3.1 改进 LLM 的位置嵌入
自注意力机制计算每个词元间的相关系数。例如,文本输入序列 “Hello”, “I”, “love”, “you” 的 \text{Softmax}(\mathbf{QK}^T) 矩阵看起来如下:
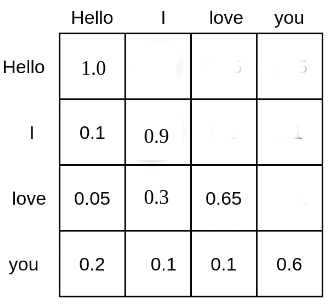
每个词元都会被赋予一个概率值,表示其对另一个词元的关注度。例如, “love” 这个词关注 “Hello” 这个词的概率为 0.05%,关注 “I” 的概率为 0.3%,而对自己的关注概率则为 0.65%。
基于自注意力但没有位置嵌入的 LLM 在理解输入文本彼此的相对位置上会遇到很大困难。这是因为在经由 \mathbf{QK}^T 来计算相关概率时,其计算是与词元间的相对距离无关的,即该计算与词元间的相对距离的关系为 O(1)。因此,对于没有位置嵌入的 LLM,每个词元似乎与所有其他词元等距。 此时 ,区分 “Hello I love you” 和 “You love I hello” 会比较困难。
为了让能够 LLM 理解语序,需要额外的 提示 ,通常我们用 位置编码 (也称为 位置嵌入 ) 来注入这种提示。位置编码将每个词元的位置编码为数字,LLM 可以利用这些数字更好地理解语序。
Attention Is All You Need 论文引入了正弦位置嵌入 \mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N 。其中每个向量 \mathbf{p}_i 为其位置 i 的正弦函数。然后将位置编码与输入序列向量简单相加 \mathbf{\hat{X}} = \mathbf{\hat{x}}_1, \ldots, \mathbf{\hat{x}}_N = \mathbf{x}_1 + \mathbf{p}_1, \ldots, \mathbf{x}_N + \mathbf{p}_N 从而提示模型更好地学习语序。
其他工作 (如 Devlin 等人的工作) 没有使用固定位置嵌入,而是使用可训练的位置编码,在训练期间学习位置嵌入 \mathbf{P}。
曾经,正弦位置嵌入以及可训练位置嵌入是将语序编码进 LLM 的主要方法,但这两个方法会有一些问题:
-
正弦位置嵌入以及可训练位置嵌入都是绝对位置嵌入, 即 为每个位置 id ( 0, \ldots, N) 生成一个唯一的嵌入。正如 Huang et al. 和 Su et al. 的工作所示,绝对位置嵌入会导致 LLM 在处理长文本输入时性能较差。对长文本输入而言,如果模型能够学习输入词元间的相对距离而不是它们的绝对位置,会比较好。
-
当使用训练位置嵌入时,LLM 必须在固定的输入长度 $N$上进行训练,因此如果推理时的输入长度比训练长度更长,外插会比较麻烦。
最近,可以解决上述问题的相对位置嵌入变得越来越流行,其中应用最多的有两个:
RoPE 和 ALiBi 都认为,最好直接在自注意力算法中向 LLM 提示语序,因为词元是通过自注意力机制互相关联的。更具体地说,应该通过修改 \mathbf{QK}^T 的计算来提示语序。
简而言之, RoPE 指出位置信息可以编码为 查询 - 键值对 , 如 \mathbf{q}_i 和 \mathbf{x}_j 通过分别将每个向量根据其在句子中的位置 i, j 旋转角度 \theta \times i 和 \theta \times j:
$$ \mathbf{\hat{q}}_i^T \mathbf{\hat{x}}_j = \mathbf{{q}} i^T \mathbf{R} {\theta, i -j} \mathbf{{x}}_j. $$
\mathbf{R}_{\theta, i - j} 表示旋转矩阵。 \theta 在不可训练的预定义值,其值取决于训练期间最大输入序列长度。
通过这样做,\mathbf{q}_i 和 \mathbf{q}_j 之间的概率得分仅受 i \ne j 是否成立这一条件影响,且其值仅取决于相对距离 i - j,而与每个向量的具体位置 i 和 j 无关。
如今,多个最重要的 LLM 使用了 RoPE ,例如:
另一个方案是 ALiBi , 它提出了一种更简单的相对位置编码方案。在计算 softmax 之前,\mathbf{QK}^T 矩阵的每个元素会减去被一个预定义系数 m 缩放后的对应两个向量间的相对距离。
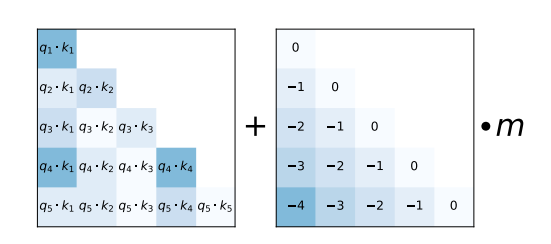
如 ALiBi 论文所示,这种简单的相对位置编码使得模型即使在很长的文本输入序列中也能保持高性能。
当前也有多个最重要的 LLM 使用了 ALiBi ,如:
RoPE 和 ALiBi 位置编码都可以外推到训练期间未见的输入长度,而事实证明,与 RoPE 相比, ALiBi 的外推效果要好得多。对于 ALiBi,只需简单地增加下三角位置矩阵的值以匹配输入序列的长度即可。而对于 RoPE ,如果输入长度比训练期间的输入长得多,使用训练期间 \theta 值的生成效果不好, 参见 Press et al.。然而,社区已经找到了一些调整 \theta 的有效技巧。从而允许 RoPE 位置嵌入能够很好地应对输入序列外插的状况 (请参阅 此处)。
RoPE 和 ALiBi 都是相对位置嵌入,其嵌入参数是 不可 训练的,而是基于以下直觉:
- 有关输入文本的位置提示应直接提供给自注意力层的 QK^T 矩阵
- 应该激励 LLM 学习基于恒定 相对 距离的位置编码
- 输入词元间彼此距离越远,它们的
查询 - 键概率越低。 RoPE 和 ALiBi 都降低了距离较远词元间的查询 - 键概率。RoPE 通过增加查询 - 键向量之间的夹角来减少它们的向量积。而 ALiBi 通过从向量积中减去一个更大的数来达成这个目的。
总之,打算部署在需要处理长文本输入的任务中的 LLM 可以通过相对位置嵌入 (例如 RoPE 和 ALiBi) 来进行更好的训练。另请注意,使用了 RoPE 和 ALiBi 的 LLM 即使是仅在固定长度 (例如 N_1 = 2048) 上训练的,其仍然可以在推理时通过位置嵌入外插来处理比 N_1 长得多的文本输入 (如 N_2 = 8192 > N_1)。
3.2 键值缓存
使用 LLM 进行自回归文本生成的工作原理是把输入序列输入给模型,并采样获得下一个词元,再将获得的词元添加到输入序列后面,如此往复,直到 LLM 生成一个表示结束的词元。
请查阅 Transformer 的文本生成教程 以更直观地了解自回归生成的工作原理。
下面,我们快速运行一个代码段来展示自回归是如何工作的。我们简单地使用 torch.argmax 获取最有可能的下一个词元。
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits = model(input_ids)["logits"][:, -1:]
next_token_id = torch.argmax(next_logits,dim=-1)
input_ids = torch.cat([input_ids, next_token_id], dim=-1)
print("shape of input_ids", input_ids.shape)
generated_text = tokenizer.batch_decode(input_ids[:, -5:])
generated_text
输出:
shape of input_ids torch.Size([1, 21])
shape of input_ids torch.Size([1, 22])
shape of input_ids torch.Size([1, 23])
shape of input_ids torch.Size([1, 24])
shape of input_ids torch.Size([1, 25])
[' Here is a Python function']
正如我们所看到的,每次我们都把刚刚采样出的词元添加到输入文本中。
除了极少数例外,LLM 都是基于因果语言模型的目标函数进行训练的,因此我们不需要注意力矩阵的上三角部分 - 这就是为什么在上面的两个图中,上三角的注意力分数是空的 ( 也即 概率为 0)。想要快速入门因果语言模型,你可以参考这篇 图解自注意力 博文。
因此,当前词元 永远仅 依赖于其前面的词元,更具体地说,\mathbf{q} _i 向量永远与任何 j > i 的键、值向量无关联。相反 \mathbf{q} _i 仅关注其之前的键、值向量 \mathbf{k}_ {m < i}, \mathbf{v}_ {m < i} \text{,} m \in {0, \ldots i - 1}。为了减少不必要的计算,因此可以把先前所有步的每一层的键、值向量缓存下来。
接下来,我们将告诉 LLM 在每次前向传播中都利用键值缓存来减少计算量。在 Transformers 中,我们可以通过将 use_cache 参数传给 forward 来利用键值缓存,这样的话,每次推理仅需传当前词元给 forward 就可以。
past_key_values = None # past_key_values is the key-value cache
generated_tokens = []
next_token_id = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits, past_key_values = model(next_token_id, past_key_values=past_key_values, use_cache=True).to_tuple()
next_logits = next_logits[:, -1:]
next_token_id = torch.argmax(next_logits, dim=-1)
print("shape of input_ids", input_ids.shape)
print("length of key-value cache", len(past_key_values[0][0])) # past_key_values are of shape [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
generated_tokens.append(next_token_id.item())
generated_text = tokenizer.batch_decode(generated_tokens)
generated_text
输出:
shape of input_ids torch.Size([1, 20])
length of key-value cache 20
shape of input_ids torch.Size([1, 20])
length of key-value cache 21
shape of input_ids torch.Size([1, 20])
length of key-value cache 22
shape of input_ids torch.Size([1, 20])
length of key-value cache 23
shape of input_ids torch.Size([1, 20])
length of key-value cache 24
[' Here', ' is', ' a', ' Python', ' function']
正如我们所看到的,当使用键值缓存时,输入文本的长度 没有 增加,每次都只有一个向量。另一方面,键值缓存的长度每解码步都增加了一。
利用键值缓存意味着 \mathbf{QK}^T 本质上减少为 \mathbf{q}_c\mathbf{K}^T,其中 \mathbf{q}_c 是当前输入词元的查询投影,它 始终 只是单个向量。
使用键值缓存有两个优点:
- 与计算完整的 \mathbf{QK}^T 矩阵相比,计算量更小,计算效率显著提高,因此推理速度也随之提高。
- 所需的最大内存不随生成的词元数量呈二次方增加,而仅呈线性增加。
用户应该 始终 使用键值缓存,因为它的生成结果相同且能显著加快长输入序列的生成速度。当使用文本 pipeline 或
generate方法 时,Transformers 默认启用键值缓存。
请注意,键值缓存对于聊天等需要多轮自回归解码的应用程序特别有用。我们看一个例子。
User: How many people live in France?
Assistant: Roughly 75 million people live in France
User: And how many are in Germany?
Assistant: Germany has ca. 81 million inhabitants
在这个聊天示例中,LLM 需自回归解码两次:
- 第一次,键值缓存为空,输入提示为
"User: How many people live in France?",模型自回归生成文本"Roughly 75 million people live in France",同时在每个解码步添加键值缓存。 - 第二次输入提示为
"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many in Germany?"。由于缓存,前两个句子的所有键值向量都已经计算出来。因此输入提示仅包含"User: And how many in Germany?"。在处理缩短的输入提示时,计算出的键值向量将添加到第一次解码的键值缓存后面。然后,助手使用键值缓存自回归地生成第二个问题的答案"Germany has ca. 81 million inhabitants",该键值缓存是"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many are in Germany?"的编码向量序列。
这里需要注意两件事:
- 保留所有上下文对于在聊天场景中部署的 LLM 至关重要,以便 LLM 理解对话的所有上文。例如,上面的示例中,LLM 需要了解用户在询问
"And how many are in Germany"时指的是人口。 - 键值缓存对于聊天非常有用,因为它允许我们不断增长聊天历史记录的编码缓存,而不必对聊天历史记录从头开始重新编码 (当使用编码器 - 解码器时架构时我们就不得不这么做)。
然而,还有一个问题。虽然 \mathbf{QK}^T 矩阵所需的峰值内存显著减少,但对于长输入序列或多轮聊天,将键值缓存保留在内存中还是会非常昂贵。请记住,键值缓存需要存储先前所有输入向量 \mathbf{x}_i \text{, for } i \in {1, \ldots, c - 1} 的所有层、所有注意力头的键值向量。
我们计算一下我们之前使用的 LLM bigcode/octocoder 需要存储在键值缓存中的浮点数的个数。浮点数的个数等于序列长度的两倍乘以注意力头的个数乘以注意力头的维度再乘以层数。假设输入序列长度为 16000,我们计算得出:
config = model.config
2 * 16_000 * config.n_layer * config.n_head * config.n_embd // config.n_head
输出:
7864320000
大约 80 亿个浮点数!以 float16 精度存储 80 亿个浮点值需要大约 15 GB 的显存,大约是模型本身权重的一半!
研究人员提出了两种方法,用于显著降低键值缓存的内存成本:
-
多查询注意力 (Multi-Query-Attention,MQA)
多查询注意力机制是 Noam Shazeer 在 Fast Transformer Decoding: One Write-Head is All You Need 论文中提出的。正如标题所示,Noam 发现,可以在所有注意力头之间共享同一对键、值投影权重,而不是使用
n_head对键值投影权重,这并不会显著降低模型的性能。通过共享同一对键、值投影权重,键值向量 \mathbf{k}_i, \mathbf{v}_i 在所有注意力头上相同,这意味着我们只需要缓存 1 个键值投影对,而不需要
n_head对。由于大多数 LLM 有 20 到 100 个注意力头,MQA 显著减少了键值缓存的内存消耗。因此,对于本文中使用的 LLM,假设输入序列长度为 16000,其所需的内存消耗从 15 GB 减少到不到 400 MB。
除了节省内存之外,MQA 还可以提高计算效率。在自回归解码中,需要重新加载大的键值向量,与当前的键值向量对相串接,然后将其输入到每一步的 \mathbf{q}_c\mathbf{K}^T 计算中。对于自回归解码,不断重新加载所需的内存带宽可能成为严重的性能瓶颈。通过减少键值向量的大小,需要访问的内存更少,从而减少内存带宽瓶颈。欲了解更多详细信息,请查看 Noam 的论文。
这里的重点是,只有使用键值缓存时,将键值注意力头的数量减少到 1 才有意义。没有键值缓存时,模型单次前向传播的峰值内存消耗保持不变,因为每个注意力头查询向量不同,因此每个注意力头的 \mathbf{QK}^T 矩阵也不相同。
MQA 已被社区广泛采用,现已被许多流行的 LLM 所采用:
此外,本文所使用的检查点 -
bigcode/octocoder- 也使用了 MQA。 -
分组查询注意力 (Grouped-Query-Attention,GQA)
分组查询注意力由来自 Google 的 Ainslie 等人提出,它们发现,与原始的多头键值投影相比,使用 MQA 通常会导致生成质量下降。该论文认为,通过不太大幅度地减少查询头投影权重的数量可以获得更高的模型性能。不应仅使用单个键值投影权重,而应使用
n < n_head个键值投影权重。通过将n设为比n_head小得多的值 (例如 2,4 或 8),几乎可以保留 MQA 带来的所有内存和速度增益,同时更少地牺牲模型能力,或者说说仅略微牺牲模型性能。此外,GQA 的作者发现,现有的模型检查点可以通过 升级训练 ,变成 GQA 架构,而其所需的计算量仅为原始预训练计算的 5%。虽然 5% 的原始预训练计算量仍然很大,但 GQA 升级训练 允许现有 checkpoint 通过这个机制,升级成能处理长输入序列的 checkpoint,这点还是挺诱人的。
GQA 最近才被提出,这就是为什么截至本文撰写时其被采用得较少。GQA 最著名的应用是 Llama-v2。
总之,如果部署自回归解码的 LLM 并且需要处理长输入序列 (例如聊天),我们强烈建议使用 GQA 或 MQA。
总结
研究界不断提出新的、巧妙的方法来加速更大的 LLM 的推理。举个例子,一个颇有前景的研究方向是 投机解码,其中“简单词元”是由更小、更快的语言模型生成的,而只有“难词元”是由 LLM 本身生成的。详细介绍超出了本文的范围,但可以阅读这篇 不错的博文。
GPT3/4、Llama-2-70b、Claude、PaLM 等海量 LLM 能够在 Hugging Face Chat 或 ChatGPT 等聊天应用中快速运行的原因是很大一部分归功于上述精度、算法和架构方面的改进。展望未来,GPU、TPU 等加速器只会变得更快且内存更大,但人们仍然应该始终确保使用最好的可用算法和架构来获得最大的收益 ![]() 。
。
英文原文: https://hf.co/blog/optimize-llm
原文作者: Patrick von Platen
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
审校/排版: zhongdongy (阿东)