本文介绍两个领先的图像分割神经网络模型: Mask2Former 和 OneFormer。相关模型已经在 ![]() Transformers 提供。
Transformers 提供。![]() Transformers 是一个开源库,提供了很多便捷的先进模型。在本文中,你也会学到各种图像分割任务的不同之处。
Transformers 是一个开源库,提供了很多便捷的先进模型。在本文中,你也会学到各种图像分割任务的不同之处。
图像分割
图像分割任务旨在鉴别区分出一张图片的不同部分,比如人物、汽车等等。从技术角度讲,图像分割任务需要根据不同的语义信息区分并聚集起对应相同语义的像素点。读者可以参考 Hugging Face 的 任务页面 来简要了解。
大体上,图像分割可以分为三个子任务: 实例分割 (instance segmentation) 、语义分割 (semantic segmentation) 、全景分割 (panoptic segmentation)。这三个子任务都有着大量的算法与模型。
- 实例分割 任务旨在区分不同的“实例”,例如图像中不同的人物个体。实例分割从某种角度看和物体检测很像,不同的是在这里我们需要的是一个对应类别的二元的分割掩膜,而不是一个检测框。实例也可以称为“物体 (objects)”或“实物 (things)”。需要注意的是,不同的个体可能在图像中是相互重叠的。
- 语义分割 区分的是不同的“语义类别”,比如属于人物、天空等类别的各个像素点。与实例分割不同的是,这里我们不需要区分开同一类别下的不同个体,例如这里我们只需要得到“人物”类别的像素级掩膜即可,不需要区分开不同的人。有些类别根本不存在个体的区分,比如天空、草地,这种类别我们称之为“东西 (stuff)”,以此区分开其它类别,称之为“实物 (things)”。请注意这里不存在不同语义类别间的重叠,因为一个像素点只能属于一个类别。
- 全景分割 在 2018 年由 Kirillov et al. 提出,目的是为了统一实例分割和语义分割。模型单纯地鉴别出一系列的图像部分,每个部分既有对应的二元掩膜,也有对应的类别标签。这些区分出来的部分,既可以是“东西”也可以是“实物”。与实例分割不同的是,不同部分间不存在重叠。
下图展示了三个子任务的不同: (图片来自 这篇博客文章)

近年来,研究者们已经推出了很多针对实例、语义、全景分割精心设计的模型架构。实例分割和全景分割基本上是通过输出一系列实例的二元掩膜和对应类别标签来处理的 (和物体检测很像,只不过这里不是输出每个实例的检测框)。这一操作也常常被称为“二元掩膜分类”。语义分割则不同,通常是让模型输出一个“分割图”,令每一个像素点都有一个标签。所以语义分割也常被视为一个“像素级分类”的任务。采用这一范式的语义分割模块包括 SegFormer 和 UPerNet。针对 SegFormer 我们还写了一篇 详细的博客。
通用图像分割
幸运的是,从大约 2020 年开始,人们开始研究能同时解决三个任务 (实例、语义和全景分割) 的统一模型。DETR 是开山之作,它通过“二元掩膜分类”的范式去解决全景分割问题,把“实物”和“东西”的类别用统一的方法对待。其核心点是使用一个 Transformer 的解码器 (decoder) 来并行地生成一系列的二元掩膜和类别。随后 MaskFormer 又在此基础上进行了改进,表明了“二元掩膜分类”的范式也可以用在语义分割上。
Mask2Former 又将此方法扩展到了实例分割上,进一步改进了神经网络的结构。因此,各自分离的子任务框架现在已经进化到了“通用图像分割”的框架,可以解决任何图像分割任务。有趣的是,这些通用模型全都采取了“掩膜分类”的范式,彻底抛弃了“像素级分类”这一方法。下图就展示了 Mask2Former 的网络结构 (图像取自 这篇论文)。
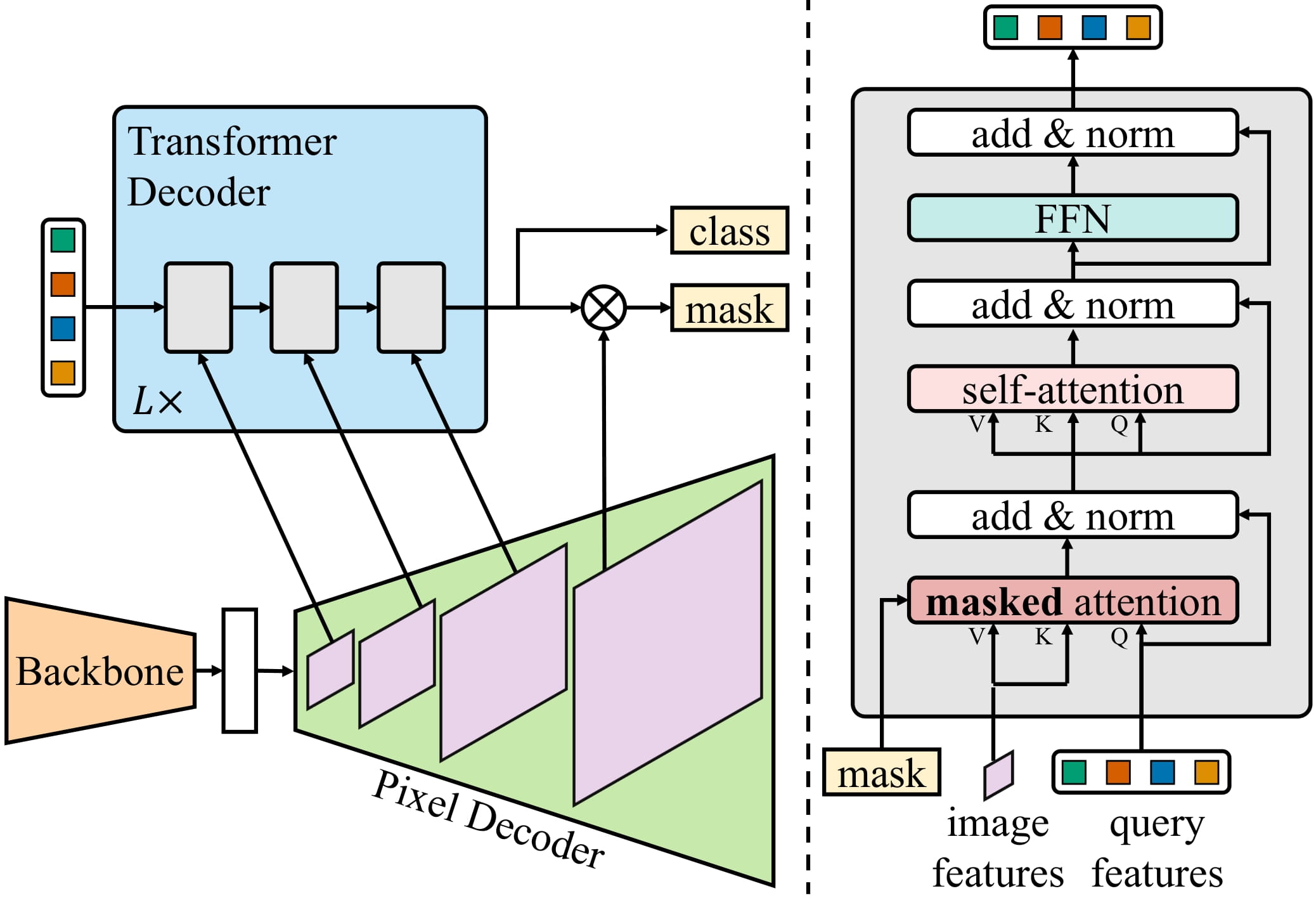
简短来说,一张图片首先被送入骨干网络 (backbone) 里面来获取一系列,在论文中,骨干网络既可以是 ResNet 也可以是 Swin Transformer。接下来,这些特征图会被一个叫做 Pixel Decoder 的模块增强成为高分辨率特征图。最终,一个 transformer 的解码器会接收一系列的 query,基于上一步得到的特征,把它们转换成一些列二元掩膜和分类预测。
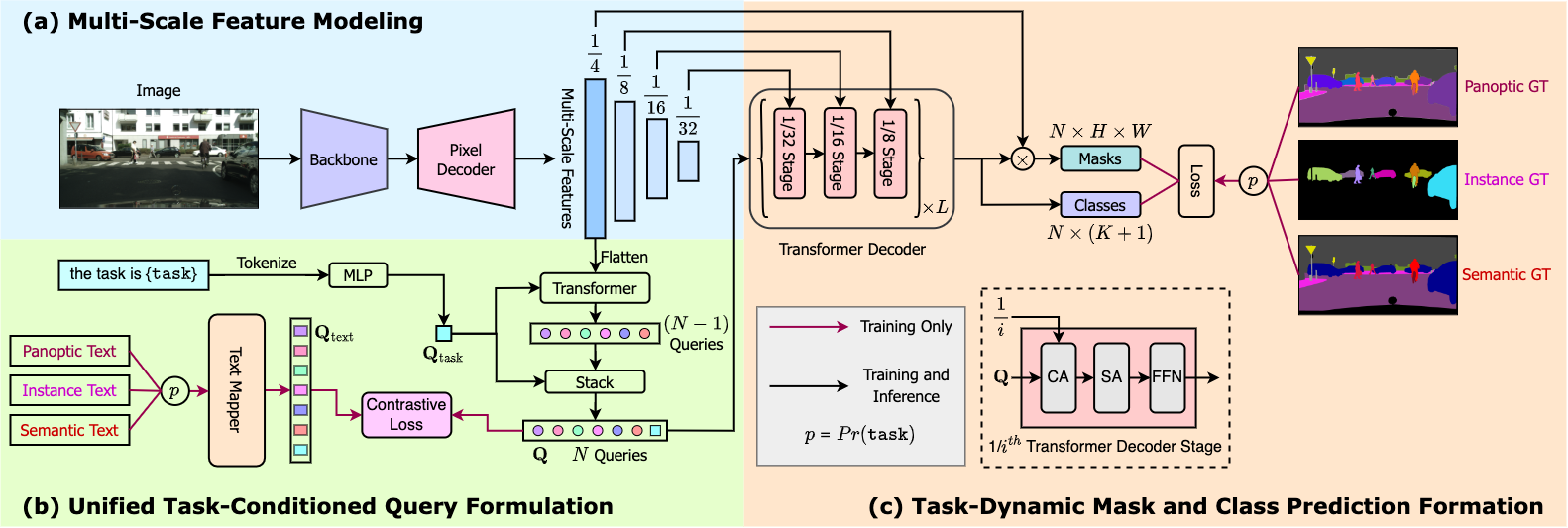
需要注意的是,MasksFormer 仍然需要在每个单独的任务上训练来获取领先的结果。这一点被 OneFormer 进行了改进,并通过在全景数据集上训练,达到了领先水平。OneFormer 增加了一个文本编码器 (text encoder),使得模型有了一个基于文本条件 (实例、语义或全景) 的输入。该模型已经收录入 ![]() Transformers 之中,比 Mask2Former 更准确,但由于文本编码器的引入,所以速度略慢。下图展示了 OneFormer 的基本结构,它使用 Swin Transformer 或 DiNAT 作为骨干网络。
Transformers 之中,比 Mask2Former 更准确,但由于文本编码器的引入,所以速度略慢。下图展示了 OneFormer 的基本结构,它使用 Swin Transformer 或 DiNAT 作为骨干网络。
使用 Transformers 库中的 Mask2Former 和 OneFormer 进行推理
使用 Mask2Former 和 OneFormer 方法相当直接,而且和它们的前身 MaskFormer 非常相似。我们这里从 Hub 中使用一个在 COCO 全景数据集上训练的一个模型来实例化一个 Mask2Former 以及对应的 processor。需要注意的是,在不同数据集上训练出来的 checkpoints 已经公开,数量不下 30 个。
from transformers import AutoImageProcessor, Mask2FormerForUniversalSegmentation
processor = AutoImageProcessor.from_pretrained("facebook/mask2former-swin-base-coco-panoptic")
model = Mask2FormerForUniversalSegmentation.from_pretrained("facebook/mask2former-swin-base-coco-panoptic")
然后我们从 COCO 数据集中找出一张猫的图片,用它来进行推理。
from PIL import Image
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image

我们使用 processor 处理原始图片,然后送入模型进行前向推理。
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
模型输出了一系列二元掩膜以及对应类别的 logit。Mask2Former 的原始输出还可以使用 processor 进行处理,来得到最终的实例、语义或全景分割结果:
prediction = processor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
print(prediction.keys())
Output:
----------------------------------------------------------------------------------------------------
dict_keys(['segmentation', 'segments_info'])
在全景分割中,最终的 prediction 包含两样东西: 一个是形状为 (height, width) 的 segmentation 图,里面针对每一个像素都给出了编码实例 ID 的值; 另一个是与之对应的 segments_info,包含了不同分割区域的更多信息 (比如类别、类别 ID 等)。需要注意的是,为了高效,Mask2Former 输出的二元掩码的形状是 (96, 96) 的,我们需要用 target_sizes 来改变尺寸,使得这个掩膜和原始图片尺寸一致。
将结果可视化出来:
from collections import defaultdict
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from matplotlib import cm
def draw_panoptic_segmentation(segmentation, segments_info):
# get the used color map
viridis = cm.get_cmap('viridis', torch.max(segmentation))
fig, ax = plt.subplots()
ax.imshow(segmentation)
instances_counter = defaultdict(int)
handles = []
# for each segment, draw its legend
for segment in segments_info:
segment_id = segment['id']
segment_label_id = segment['label_id']
segment_label = model.config.id2label[segment_label_id]
label = f"{segment_label}-{instances_counter[segment_label_id]}"
instances_counter[segment_label_id] += 1
color = viridis(segment_id)
handles.append(mpatches.Patch(color=color, label=label))
ax.legend(handles=handles)
draw_panoptic_segmentation(**panoptic_segmentation)
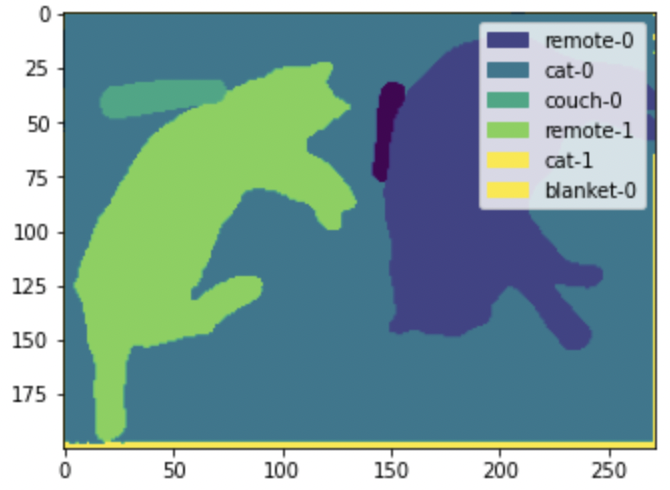
可以看到,模型区分开了不同的猫和遥控器。相比较而言,语义分割只会为“猫”这一种类创建一个单一的掩膜。
如果你想试试 OneFormer,它和 Mask2Former 的 API 几乎一样,只不过多了一个文本提示的输入; 可以参考这里的 demo notebook。
使用 transformers 微调 Mask2Former 和 OneFormer
读者可以参考这里的 demo notebooks 来在自定义的实例、语义或全景分割数据集上微调 Mask2Former 或 OneFormer 模型。MaskFormer、Mask2Former 和 OneFormer 都有着相似的 API,所以基于 MaskFormer 进行改进十分方便、需要的修改很少。
在上述 notebooks 中,都是使用 MaskFormerForInstanceSegmentation 来加载模型,而你需要换成使用 Mask2FormerForUniversalSegmentation 或 OneFormerForUniversalSegmentation。对于 Mask2Former 中的图像处理,你也需要使用 Mask2FormerImageProcessor。你也可以使用 AutoImageProcessor 来自动地加载适合你的模型的 processor。OneFormer 则需要使用 OneFormerProcessor,因为它不仅预处理图片,还需要处理文字。
总结
总的来说就这些内容!你现在知道实例分割、语义分割以及全景分割都有什么不同了,你也知道如何使用 ![]() Transformers 中的 Mask2Former 和 OneFormer 之类的“通用架构”了。
Transformers 中的 Mask2Former 和 OneFormer 之类的“通用架构”了。
我们希望你喜欢本文并学有所学。如果你微调了 Mask2Former 或 OneFormer,也请让我们知道你是否对结果足够满意。
如果想深入学习,我们推荐以下资源:
- 我们针对 MaskFormer, Mask2Former and OneFormer, 推出的 demo notebooks,将会给出更多关于推理 (包括可视化) 和微调的知识。
- 在 Hugging Face Hub 上, Mask2Former 和 OneFormer 的 live demo spaces,可以让你快速用自己的输入数据尝试不同模型。
原文链接: https://hf.co/blog/mask2former
作者: Niels Rogge、Shivalika Singh、Alara Dirik
译者: Hoi2022
审校、排版: zhongdongy (阿东)