
最近,人工智能社区在开发更大、更高性能的语言模型方面取得了显著的进展,例如 Falcon 40B、LLaMa-2 70B、Falcon 40B、MPT 30B; 以及在图像领域的模型,如 SD2.1 和 SDXL 。这些进步无疑推动了人工智能的发展,使其具有高度多功能和最先进的图像生成和语言理解能力。然而,在我们惊叹于这些模型的强大和复杂性之余,必须认识到一个日益增长的需求: 使人工智能模型体量更小、运行更高效、更易于访问,特别是通过开源它们来共建生态。
在 Segmind,我们一直致力于如何使生成式 AI 更快、更便宜。去年,我们开源了我们加速的 SD-WebUI 库 voltaML,它是一个基于 AITemplate/TensorRT 的推理加速库,推理速度提高了 4-6 倍。为了继续实现使生成模型更快、更小、更便宜的目标,我们正在开源我们压缩的 SD 模型:SD-Small 和 SD-Tiny 的权重和训练代码。预训练的检查点可在 Hugging Face ![]() 上获取。
上获取。
知识蒸馏

我们的新压缩模型已经经过知识蒸馏 (KD) 技术的训练,这项工作主要基于 这篇论文。作者描述了一种块移除知识蒸馏方法,其中一些 UNet 层被移除,学生模型权重被训练。使用论文中描述的 KD 方法,我们能够使用 ![]() diffusers 库训练两个压缩模型; Small(微小版本) 和 Tiny(极小版本),分别比基础模型少 35% 和 55% 的参数,同时实现与基础模型相当的图像保真度。我们已经在这个 repo 中开源了我们的蒸馏代码,并将预训练检查点上传到了 Hugging Face
diffusers 库训练两个压缩模型; Small(微小版本) 和 Tiny(极小版本),分别比基础模型少 35% 和 55% 的参数,同时实现与基础模型相当的图像保真度。我们已经在这个 repo 中开源了我们的蒸馏代码,并将预训练检查点上传到了 Hugging Face ![]() 。
。
知识蒸馏训练神经网络类似于老师一步一步指导学生。一个大的老师模型 (teacher model) 预先在大量数据上训练,然后一个较小的模型在较小的数据集上训练,以模仿大模型的输出并在数据集上进行经典训练。
在这种特殊类型的知识蒸馏中,学生模型被训练来完成从纯噪声恢复图像的正常扩散任务,但同时,模型被迫与更大的老师模型的输出匹配。输出匹配发生在 U-nets 的每个块,因此模型质量基本保持不变。所以,使用前面的类比,我们可以说,在这种蒸馏过程中,学生不仅会试图从问题和答案中学习,还会从老师的答案以及逐步得到答案的方法中学习。我们在损失函数中有 3 个组成部分来实现这一点,首先是目标图像隐变量和生成图像隐变量之间的传统损失。其次是老师生成的图像隐变量和学生生成的图像隐变量之间的损失。最后,也是最重要的组成部分,是特征级损失,即老师和学生每个块输出之间的损失。
结合所有这些构成了知识蒸馏训练。下面是论文中描述的用于 KD 的块移除 UNet 架构。
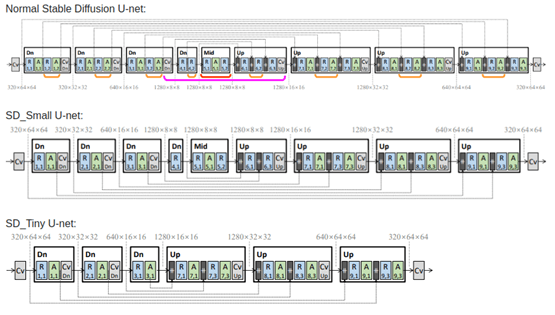
图片来自 Shinkook 等人的 论文 “On Architectural Compression of Text-to-Image Diffusion Models”。
我们以 Realistic-Vision 4.0 为基础老师模型,并在LAION Art Aesthetic 数据集 上训练,图像分数高于 7.5,因为它们具有高质量的图像描述。与论文不同,我们选择分别为 Small 和 Tiny 模式训练两个模型,分别在 1M 张图像上进行 100K 步和 125K 步的训练。蒸馏训练的代码可以在 这里 找到。
模型使用
模型可以通过 ![]() diffusers 中的 DiffusionPipeline 来使用。
diffusers 中的 DiffusionPipeline 来使用。
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("segmind/small-sd", torch_dtype=torch.float16)
prompt = "Portrait of a pretty girl"
negative_prompt = "(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck"
image = pipeline(prompt, negative_prompt = negative_prompt).images[0]
image.save("my_image.png")
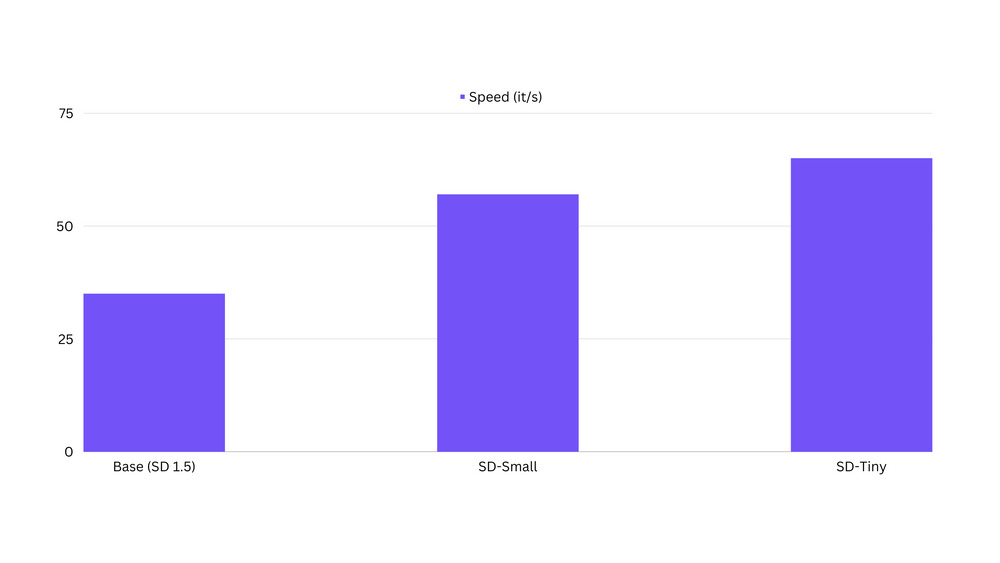
推理延迟方面的速度表现
我们观察到,蒸馏模型比原始基础模型快了一倍。基准测试代码可以在 这里 找到。
潜在的局限性
蒸馏模型处于早期阶段,输出可能还不具备生产水平的质量。这些模型可能不是最好的通用模型,它们最好用作针对特定概念/风格进行微调或 LoRA 训练。蒸馏模型目前还不太擅长组合性或多概念。
在人像数据集上微调 SD-tiny 模型
我们已经在 Realistic Vision v4.0 模型生成的人像图像上微调了我们的 sd-tiny 模型。下面是使用的微调参数。
| 原版参数 | 中文释义 |
|---|---|
| Steps: 131000 | 步数: 131000 |
| Learning rate: 1e-4 | 学习率: 1e-4 |
| Batch size: 32 | 批量大小: 32 |
| Gradient accumulation steps: 4 | 梯度累积步数: 4 |
| Image resolution: 768 | 图像分辨率: 768 |
| Dataset size: 7k images | 数据集大小: 7 千张图像 |
| Mixed precision: fp16 | 混合精度: fp16 |
我们能够产生接近原始模型产生的图像质量,参数减少了近 40%,下面的样本结果不言自明:

微调基础模型的代码可以在 这里 找到。
LoRA 训练
在蒸馏模型上进行 LoRA 训练的一个优点是训练更快。下面是我们在蒸馏模型上对一些抽象概念进行的第一个 LoRA 训练的一些图像。LoRA 训练的代码可以在 这里 找到。

结论
我们邀请开源社区帮助我们改进并实现这些蒸馏 SD 模型的更广泛采用。用户可以加入我们的 Discord 服务器,在那里我们将宣布这些模型的最新更新,发布更多的检查点和一些令人兴奋的新 LoRAs。如果你喜欢我们的工作,请在我们的 Github 上点一下 star。
英文原文: https://hf.co/blog/sd_distillation
原文作者: Yatharth Gupta
译者: innovation64
审校/排版: zhongdongy (阿东)