随着数据集的使用量急剧增加,Hugging Face 社区已经变成了众多数据集默认存放的仓库。每月,海量数据集被上传到社区,这些数据集亟需有效的查询、过滤和发现。

每个月在 Hugging Face Hub 创建的数据集
我们现在非常激动地宣布,您可以直接在 Hugging Face 社区中对您的数据集进行 SQL 查询!
数据集的 SQL 控制台介绍
在每个公共数据集中,您应该会看到一个新的 SQL 控制台标签。只需单击即可打开 SQL 控制台以查询该数据集。
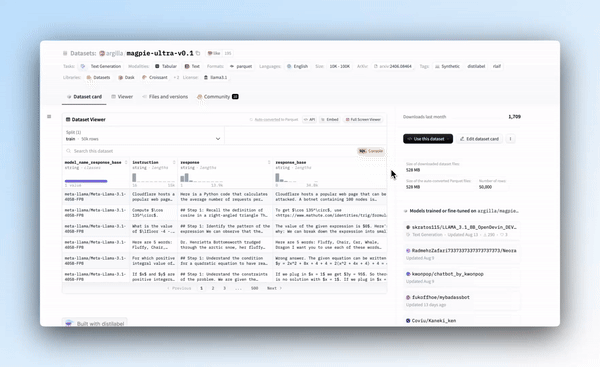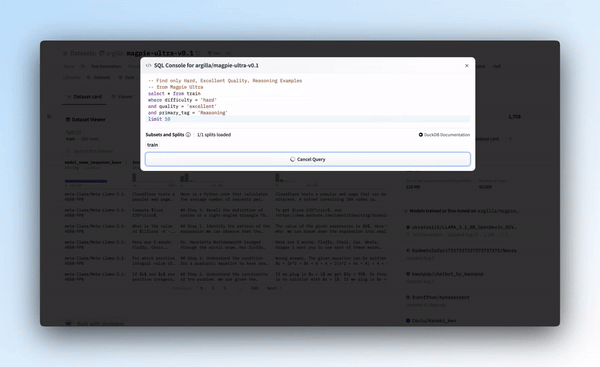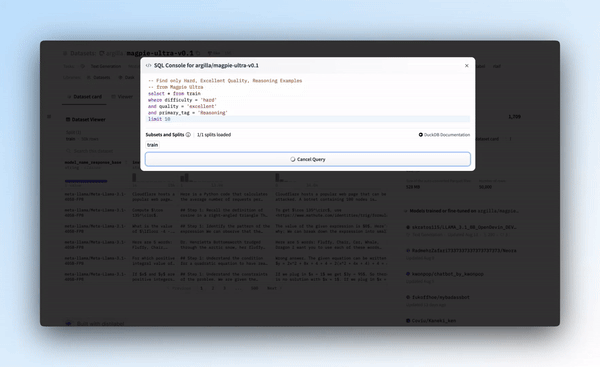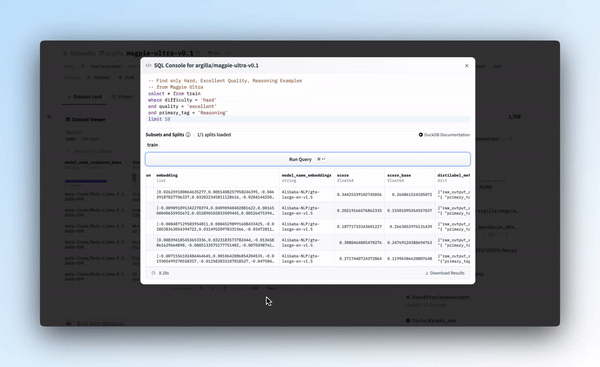
查询 Magpie-Ultra 数据集来获取优秀的高质量推理指令。
所有的操作都在浏览器中完成,控制台还配备了一些实用的功能:
- 完全的本地化支持: SQL 控制台由 DuckDB WASM 驱动,因此您可以无需任何依赖即可查询您的数据集。
- 完整的 DuckDB 语法支持: DuckDB 支持全面的 SQL 语句,并包含许多内置函数,如正则表达式、列表、JSON、嵌入等。您会发现 DuckDB 的语法与 PostgreSQL 非常相似。
- 结果导出: 您可以将查询的结果导出为 parquet 格式 .
- 分享: 您可以使用链接分享公共数据集的查询结果 .
工作原理
Parquet 格式转换
大多数在 Hugging Face 上的数据集都存储为 Parquet 格式,这是一种优化了性能和存储效率的列式数据格式。Hugging Face 的 数据集视图 和 SQL 控制台会直接从数据集的 Parquet 文件中加载数据。如果数据集是以其他格式存储的,则前 5GB 自动转换为 Parquet 格式。您可以在 Dataset Viewer Parquet API 文档 中找到更多关于 Parquet 转换过程的信息。
使用这些 Parquet 文件,SQL 控制台会为您创建视图,基于数据集的划分和配置供您进行查询。
DuckDB WASM  引擎
引擎
DuckDB WASM 是驱动 SQL 控制台的引擎。它是一个在浏览器中运行于 Web Assembly 的进程内数据库引擎,无需服务器或后端。
仅在浏览器中运行,它为用户提供最大程度的灵活性,可以自由查询数据而不需要任何依赖项。这也使得通过简单的链接分享可复现的结果变得非常简单。
你可能在想,“这是否适用于大数据集?”答案是“当然可以!
以下是对 OpenCo7/UpVoteWeb 数据集的查询,该数据集经过 Parquet 格式转换后有 12.6M 行。
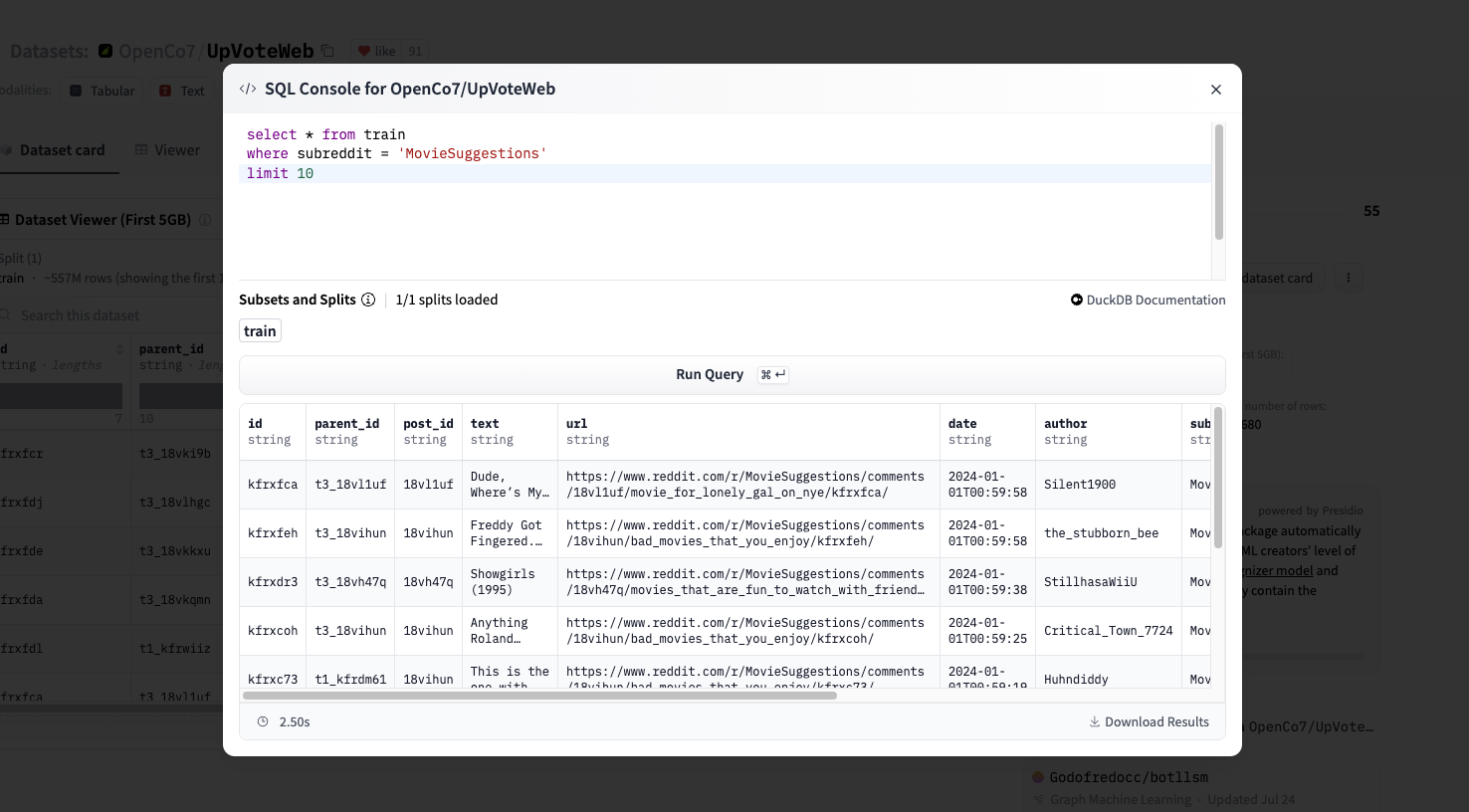
您可以看到,我们在不到 3 秒内的时间内收到了简单过滤查询的结果。
虽然基于数据集的大小和查询的复杂度查询可能会发生很长时间,您会感到吃惊您用 SQL 控制台做到的事情。
就像任何技术一样,也有其局限性:
- SQL 控制台可以处理许多查询。然而内存限制约为 3GB,因此有可能超出内存并无法处理查询 (提示: 尝试使用过滤器来减少您正在查询的数据量,并结合使用
LIMIT)。 - 尽管 DuckDB WASM 非常强大,但它并不完全与 DuckDB 功能一致。例如,DuckDB WASM 尚未支持
hf://协议以查询数据集。
示例: 将数据集从 Alpaca 转换为对话格式
现在我们已经介绍了 SQL 控制台,让我们通过一个实际例子来实践一下。当微调大型语言模型时,我们经常需要处理不同的数据格式。其中特别流行的一种格式是对话式格式,在这种格式中,每一行代表用户与模型之间的多轮对话。SQL 控制台可以帮助我们高效地将数据转换为这种格式。让我们看看如何使用 SQL 将 Alpaca 数据集转换为对话式格式。
通常开发人员会通过 Python 预处理步骤来完成这项任务,但我们可以展示一下在不到 30 秒的时间内利用 SQL 控制台实现相同的功能。
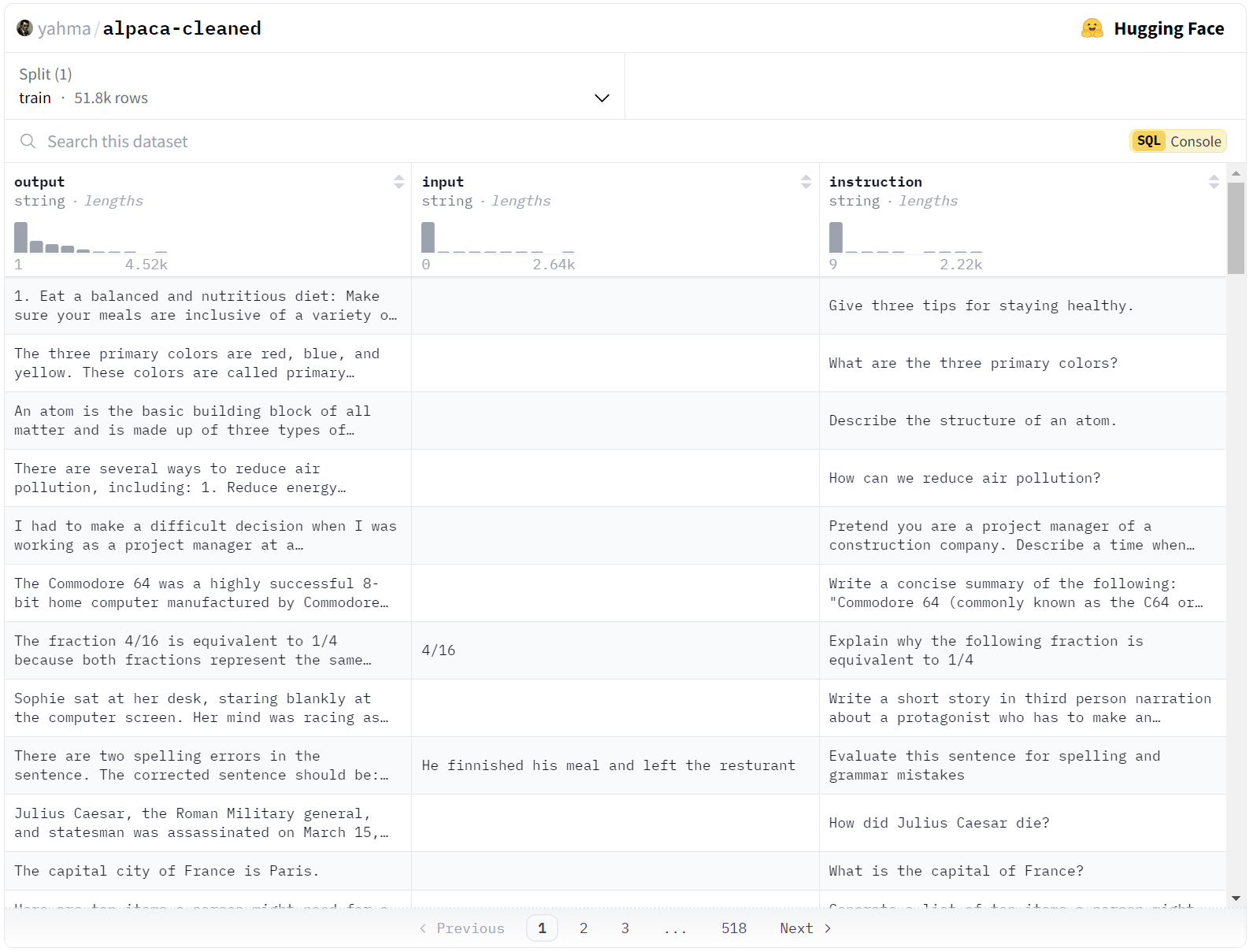
在上方的数据集中,点击 SQL 控制台 标签以打开 SQL 控制台。您应该会看到下方的查询已自动填充。
SQL
-- Convert Alpaca format to Conversation format
WITH
source_view AS (
SELECT * FROM train -- Change 'train' to your desired view name here
)
SELECT
[
struct_pack(
"from" := 'user',
"value" := CASE
WHEN input IS NOT NULL AND input != ''
THEN instruction || '\n\n' || input
ELSE instruction
END
),
struct_pack(
"from" := 'assistant',
"value" := output
)
] AS conversation
FROM source_view
WHERE instruction IS NOT NULL
AND output IS NOT NULL;
我们在查询中使用 struct_pack 函数为每个对话创建一个新的 STRUCT 行
DuckDB 对结构化的数据类型和函数有很好的文档说明,你可以参考 数据类型 和 函数。你会发现许多数据集包含带有 JSON 数据的列。DuckDB 提供了易于解析和查询这些列的功能。
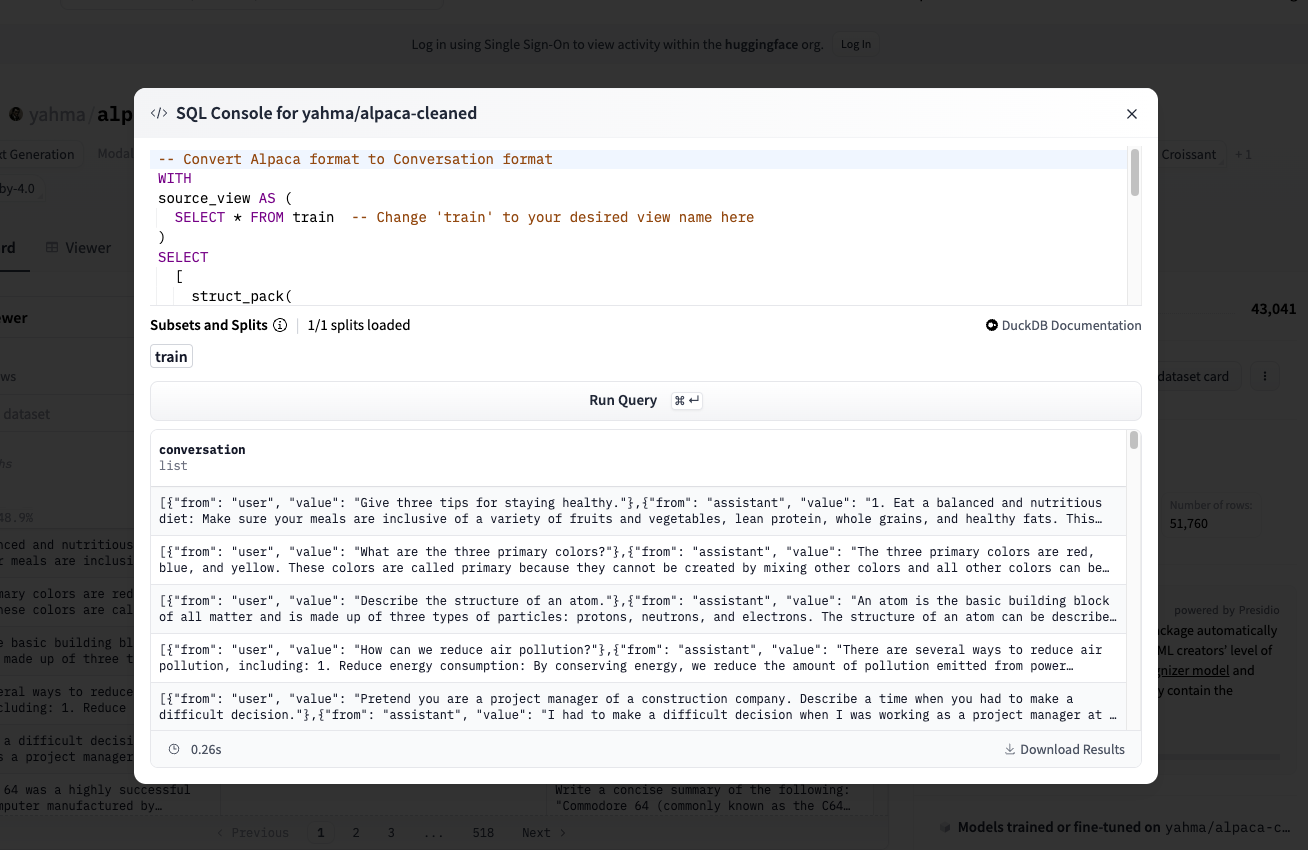
一旦我们得到结果,就可以将其下载为一个 Parquet 文件。你可以在下面看到最终输出的样子。
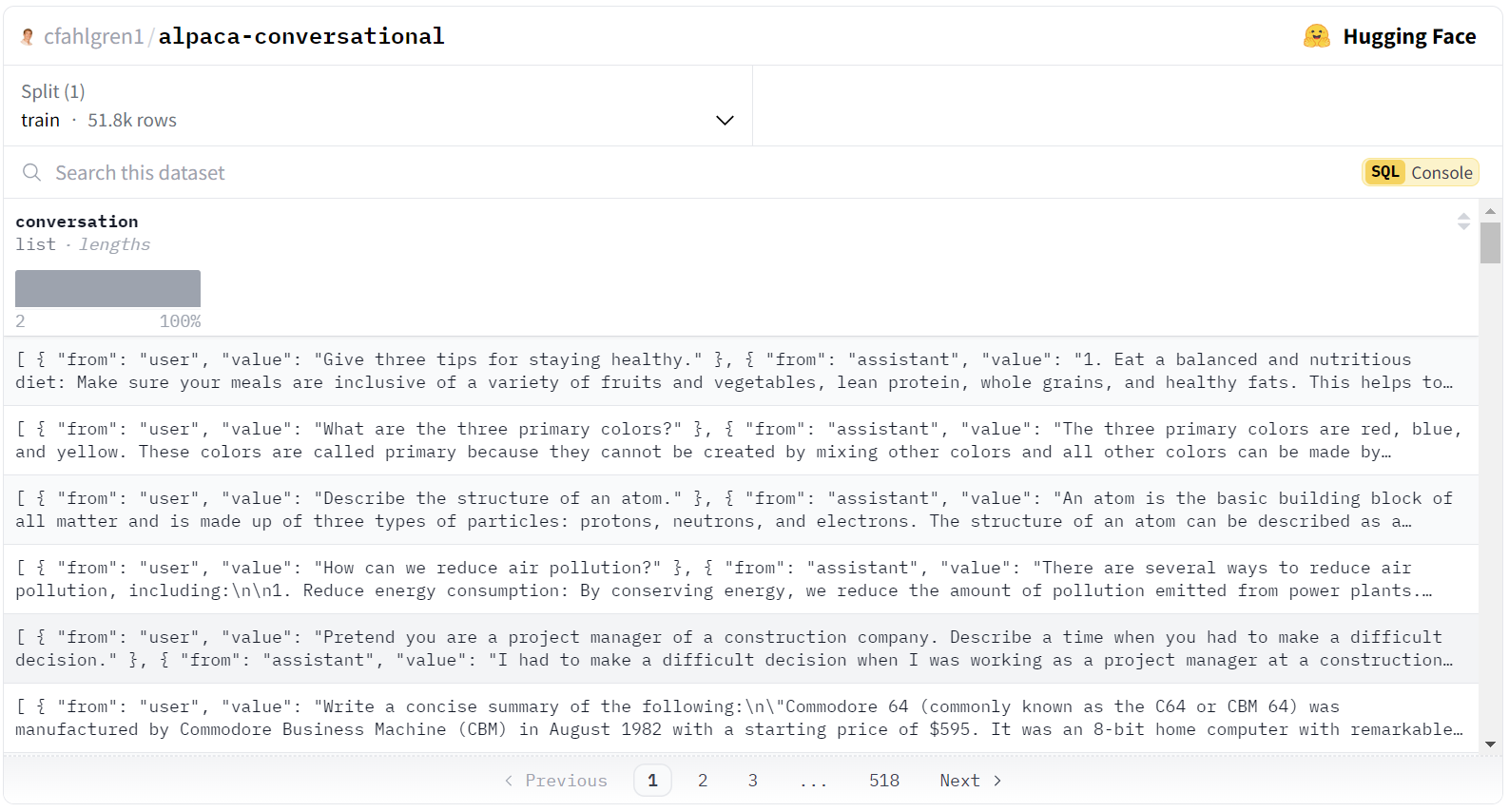
试一下!
作为另一个例子,你可以尝试对 SkunkworksAI/reasoning-0.01 运行一个 SQL 控制台查询,以查看包含超过 10 个推理步骤的指令。
SQL 片段
DuckDB 有许多我们仍在探索的应用场景。我们创建了一个 SQL 片段 空间,以展示您可以在 SQL 控制台中完成的操作。
这里有一些非常有趣的用例:
- 使用正则表达式过滤调用特定函数的数据集
- 从开放 LLM 排行榜中找到最受欢迎的基础模型
- 将 alpaca 数据集转换为对话格式
- 使用嵌入进行相似性搜索
- 从数据集中过滤超过 5 万行以获取最高质量的推理指令
请记住,只需点击一下即可下载您的 SQL 结果作为 Parquet 文件并用于数据集!
我们非常希望听听您对 SQL 控制台的看法,如果您有任何反馈,请在以下 帖子中留言!
资源
英文原文: https://hf.co/blog/sql-console
原文作者: Caleb Fahlgren
译者: smartisan