本文主要探讨 TGI 的小兄弟 - TGI 基准测试工具。它能帮助我们超越简单的吞吐量指标,对 TGI 进行更全面的性能剖析,以更好地了解如何根据实际需求对服务进行调优并按需作出最佳的权衡及决策。如果你曾觉得 LLM 服务部署成本太高,或者你想对部署进行调优,那么本文很适合你!
我将向大家展示如何轻松通过 Hugging Face 空间 进行服务性能剖析。你可以把获得的分析结果用于 推理端点 或其他相同硬件的平台的部署。
动机
为了更好地理解性能剖析的必要性,我们先讨论一些背景信息。
大语言模型 (LLM) 从根子上来说效率就比较低,这主要源自其基于 解码器的工作方式,每次前向传播只能生成一个新词元。随着 LLM 规模的扩大以及企业 采用率的激增,AI 行业围绕优化手段创新以及性能提优技术做了非常出色的工作。
在 LLM 推理服务优化的各个方面,业界积累了数十项改进技术。各种技术层出不穷,如: Flash Attention、Paged Attention、流式响应、批处理改进、投机解码、各种各样的 量化 技术、前端网络服务改进,使用 更快的语言 (抱歉,Python ![]() !) 等等。另外还有不少用例层面的改进,如 结构化生成 以及 水印 等都在当今的 LLM 推理世界中占据了一席之地。我们深深知道,LLM 推理服务优化没有万能灵丹,一个快速高效的推理服务需要整合越来越多的细分技术 $^{[1]}$。
!) 等等。另外还有不少用例层面的改进,如 结构化生成 以及 水印 等都在当今的 LLM 推理世界中占据了一席之地。我们深深知道,LLM 推理服务优化没有万能灵丹,一个快速高效的推理服务需要整合越来越多的细分技术 $^{[1]}$。
TGI 是 Hugging Face 的高性能 LLM 推理服务,其宗旨就是拥抱、整合、开发那些可用于优化 LLM 部署和使用的最新技术。由于 Hugging Face 的强大的开源生态,大多数 (即使不是全部) 主要开源 LLM 甫一发布即可以在 TGI 中使用。
一般来讲,实际应用的不同会导致用户需求迥异。以 RAG 应用 的提示和生成为例:
- 指令/格式
- 通常很短,<200 个词元
- 用户查询
- 通常很短,<200 个词元
- 多文档
- 中等大小,每文档 500-1000 个词元,
- 文档个数为 N,且 N<10
- 响应
- 中等长度 , ~500-1000 个词元
在 RAG 应用中,将正确的文档包含于提示中对于获得高质量的响应非常重要,用户可以通过包含更多文档 (即增加 N) 来提高这种概率。也就是说,RAG 应用通常会尝试最大化 LLM 的上下文窗口以提高任务性能。而一般的聊天应用则相反,典型 聊天场景 的词元比 RAG 少得多:
- 多轮对话
- 2xTx50-200 词元,T 轮
- 2x 的意思是每轮包括一次用户输入和一次助理输出
鉴于应用场景如此多样,我们应确保根据场景需求来相应配置我们的 LLM 服务。为此,Hugging Face 提供了一个 基准测试工具,以帮助我们探索哪些配置更适合目标应用场景。下文,我将解释如何在 Hugging Face 空间 上使用该基准测试工具。
Pre-requisites
在深入研究基准测试工具之前,我们先对齐一下关键概念。
延迟与吞吐

图 1: 延迟与吞吐量的可视化解释
- 词元延迟 – 生成一个词元并将其返回给用户所需的时间
- 请求延迟 – 完全响应请求所需的时间
- 首词元延迟 - 从请求发送到第一个词元返回给用户的时间。这是处理预填充输入的时间和生成第一个词元的时间的和
- 吞吐量 – 给定时间内服务返回的词元数 (在本例中,吞吐量为每秒 4 个词元)
延迟是一个比较微妙的测量指标,它无法反应全部情况。你的生成延迟可能比较长也可能比较短,但长也好短也罢,并不能完整刻画实际的服务性能。
我们需要知道的重要事实是: 吞吐和延迟是相互正交的测量指标,我们可以通过适当的服务配置,针对其中之一进行优化。我们的基准测试工具可以对测量数据进行可视化,从而帮助大家理解折衷之道。
预填充与解码
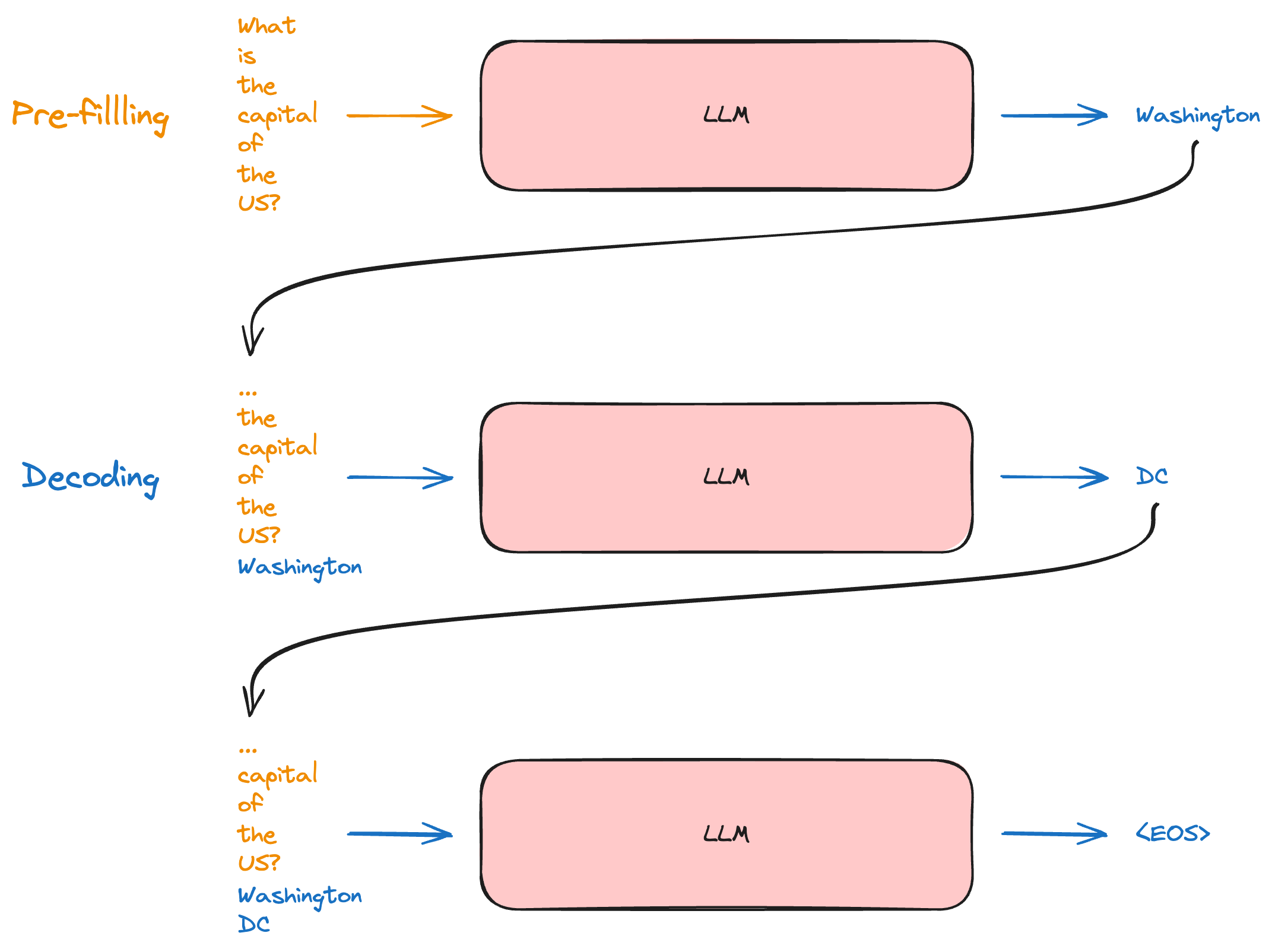
图 2: 预填充与解码图解,灵感来源 ^{[2]}
以上给出了 LLM 如何生成文本的简图。一般,模型每次前向传播生成一个词元。在 预填充阶段 (用橙色表示),模型会收到完整的提示 (What is the capital of the US?) 并依此生成首个词元 (Washington)。在 解码阶段 (用蓝色表示),先前生成的词元被添加进输入 (What is the capital of the US? Washington),并馈送给模型以进行新一轮前向传播。如此往复: 向模型馈送输入 → 生成词元 → 将词元添加进输入,直至生成序列结束词元 ()。
点击揭晓答案
因为我们无需生成 “What is the” 的下一个词元,我们已经知道它是 “capital” 了。为了易于说明,上图仅选择了一个短文本生成示例,但注意,预填充仅需要模型进行一次前向传播,但解码可能需要数百次或更多的前向传播,即使在上述短文本示例中,我们也可以蓝色箭头多于橙色箭头。我们现在可以明白为什么要花这么多时间才能等到 LLM 的输出了!由于前向次数较多,解码阶段通常是我们花心思更多的地方。
基准测试工具
动机
在对工具、新算法或模型进行比较时,吞吐量是大家常用的指标。虽然这是 LLM 推理故事的重要组成部分,但单靠吞吐量还是缺少一些关键信息。一般来讲,我们至少需要知道吞吐量和延迟两个指标才能作出正确的决策 (当然你增加更多指标,以进行更深入的研究)。TGI 基准测试工具就支持你同时得到延迟和吞吐量两个指标。
另一个重要的考量是你希望用户拥有什么体验。你更关心为许多用户提供服务,还是希望每个用户在使用你的系统后都能得到快速响应?你想要更快的首词元延迟 (TTFT,Time To First Token),还是你能接受首词元延迟,但希望后续词元的速度要快?
下表列出了对应于不同目标的不同关注点。请记住,天下没有免费的午餐。但只要有足够的 GPU 和适当的配置,“居天下有甚难”?
| 我关心 ...... | 我应专注于 ...... |
| 处理更多的用户 | 最大化吞吐量 |
| 我的网页/应用正在流失用户 | 最小化 TTFT |
| 中等体量用户的用户体验 | 最小化延迟 |
| 全面的用户体验 | 在给定延迟内最大化吞吐量 |
环境搭建
基准测试工具是随着 TGI 一起安装的,但你需要先启动服务才能运行它。为了简单起见,我设计了一个空间 - derek-thomas/tgi-benchmark-space,其把 TGI docker 镜像 (固定使用最新版) 和一个 jupyter lab 工作空间组合起来,从而允许我们部署选定的模型,并通过命令行轻松运行基准测试工具。这个空间是可复制的,所以如果它休眠了,请不要惊慌,复制一个到你的名下就可以了。我还在空间里添加了一些 notebook,你可以参照它们轻松操作。如果你想对 Dockerfile 进行调整,请随意研究,以了解其构建方式。
起步
请注意,由于其交互性,在 jupyter lab 终端中运行基准测试工具比在 notebook 中运行要好得多,但我还是把命令放在 notebook 中,这样易于注释,并且很容易照着做。
- 点击 “Duplicate this space” 按钮
- 在 空间密令 中设置你自己的
JUPYTER_TOKEN默认密码 (系统应该会在你复制空间时提示你) - 选择硬件,注意它应与你的最终部署硬件相同或相似
- 进入你的空间并使用密码登录
- 启动
01_1_TGI-launcher.ipynb
- 其会用 jupyter notebook 以默认设置启动 TGI
- 启动
01_2_TGI-benchmark.ipynb
- 其会按照指定设置启动 TGI 基准测试工具
主要区块
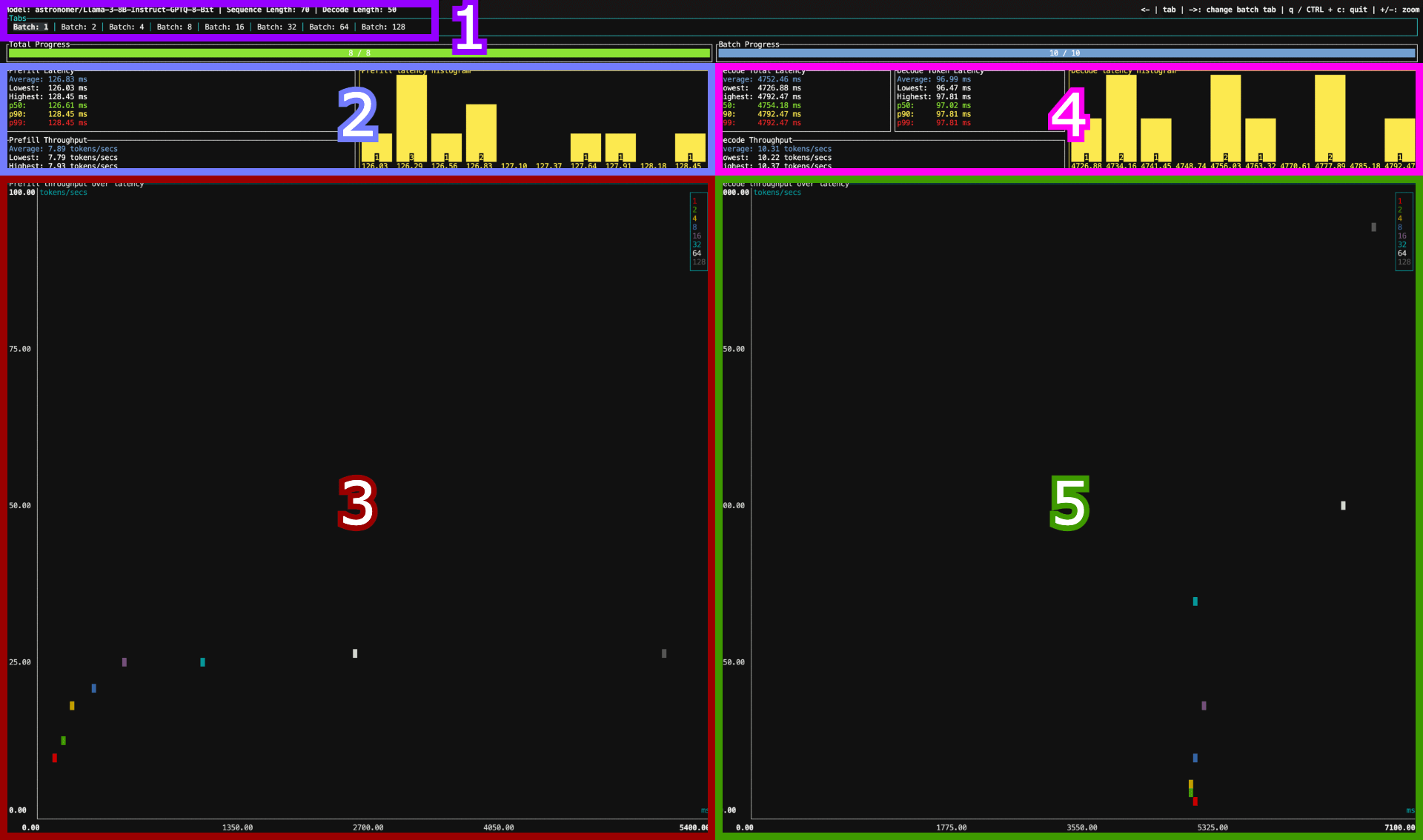
图 3:基准测试报告区块
- 区块 1: batch size 选项卡及其他信息。
- 使用箭头选择不同的 batch size
- 区块 2 及 区块 4: 预填充/解码阶段的统计信息及直方图
- 基于
--runs的数量计算的统计数据/直方图
- 基于
- 区块 3 及 区块 5: 预填充/解码阶段的
延迟 - 吞吐量散点图- X 轴是延迟 (越小越好)
- Y 轴是吞吐量 (越大越好)
- 图例是 batch size
- “ 理想 ”点位于左上角 (低延迟、高吞吐)
理解基准测试工具
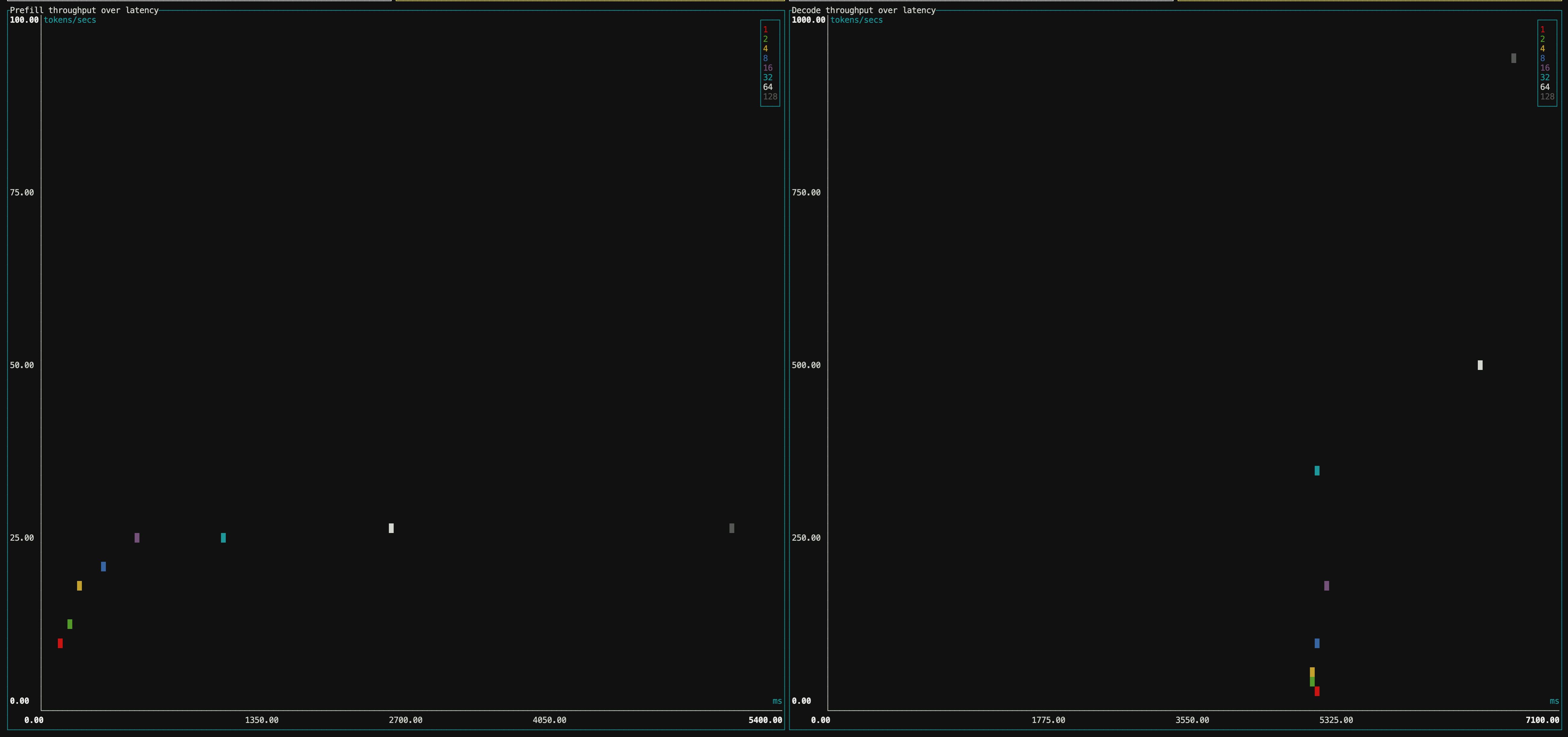
图 4:基准测试工具散点图
如果你的硬件和设置与我相同,应该会得到与图 4 类似的图。基准测试工具向我们展示了: 在当前设置和硬件下,不同 batch size (代表用户请求数,与我们启动 TGI 时使用的术语略有不同) 下的吞吐量和延迟。理解这一点很重要,因为我们应该根据基准测试工具的结果来调整 TGI 的启动设置。
如果我们的应用像 RAG 那样预填充较长的话, 区块 3 的图往往会更有用。因为,上下文长度的确会影响 TTFT (即 X 轴),而 TTFT 是用户体验的重要组成部分。请记住,虽然在预填充阶段我们必须从头开始构建 KV 缓存,但好处是所有输入词元的处理可以在一次前向传播中完成。因此,在许多情况下,就每词元延迟而言,预填充确实比解码更快。
区块 5 中的图对应于解码阶段。我们看一下数据点的形状,可以看到,当 batch size 处于 1~32 的范围时,形状基本是垂直的,大约为 5.3 秒。这种状态就相当不错,因为这意味着在不降低延迟的情况下,我们可以显著提高吞吐量!64 和 128 会怎么样呢?我们可以看到,虽然吞吐量在增加,但延迟也开始增加了,也就是说出现了折衷。
对于同样的 batch size,我们再看看 区块 3 图的表现。对 batch size 32,我们可以看到 TTFT 的时间仍然约为 1 秒。但我们也看到从 32 → 64 → 128 延迟出现了线性增长,2 倍的 batch size 的延迟也是 2 倍。此外,没有吞吐量增益!这意味着我们并没有真正从这种折衷中获得太多好处。
- 如果添加更多的数据点,你觉得其形状会如何呢?
- 如果词元数增加,你举得这些散点 (预填充抑或解码) 的形状会如何变化呢?
如果你的 batch size 落在垂直区,很好,你可以获得更多的吞吐量并免费处理更多的用户。如果你的 batch size 处于水平区,这意味着你受到算力的限制,每增加一个用户都会损害每个人的延迟,且不会带来任何吞吐量的好处。你应该优化你的 TGI 配置或扩展你的硬件。
现在我们已经了解了 TGI 在各种场景中的行为,我们可以多尝试几个不同的 TGI 设置并对其进行基准测试。在选定一个好的配置之前,最好先多试几次。如果大家有兴趣的话,或许我们可以写个续篇,深入探讨针对聊天或 RAG 等不同用例的优化。
尾声
追踪实际用户的行为非常重要。当我们估计用户行为时,我们必须从某个地方开始并作出有根据的猜测。这些数字的选择将对我们的剖析质量有重大影响。幸运的是,TGI 会在日志中告诉我们这些信息,所以请务必检查日志。
一旦探索结束,请务必停止运行所有程序,以免产生进一步的费用。
- 终止
TGI-launcher.ipynbjupyter notebook 中正在运行的单元 - 在终端中点击
q以终止运行分析工具 - 在空间设置中点击暂停
总结
LLM 规模庞大且昂贵,但有多种方法可以降低成本。像 TGI 这样的 LLM 推理服务已经为我们完成了大部分工作,我们只需善加利用其功能即可。首要工作是了解现状以及你可以做出哪些折衷。通过本文,我们已经了解如何使用 TGI 基准测试工具来做到这一点。我们可以获取这些结果并将其用于 AWS、GCP 或推理终端中的任何同等硬件。
感谢 Nicolas Patry 和 Olivier Dehaene 创建了 TGI 及其 基准测试工具。还要特别感谢 Nicholas Patry、Moritz Laurer、Nicholas Broad、Diego Maniloff 以及 Erik Rignér 帮忙校对本文。
参考文献
- [1]: Sara Hooker, The Hardware Lottery, 2020
- [2]: Pierre Lienhart, LLM Inference Series: 2. The two-phase process behind LLMs’ responses, 2023
英文原文: https://hf.co/blog/tgi-benchmarking
原文作者: Derek Thomas
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。