大型语言模型如今风靡一时,许多公司投入大量资源来扩展它们规模并解锁新功能。然而,作为注意力持续时间不断缩短的人类,我们并不喜欢大模型缓慢的响应时间。由于延迟对于良好的用户体验至关重要,人们通常使用较小的模型来完成任务,尽管它们的质量较低 (例如 代码补全任务)。
为什么文本生成这么慢?是什么阻止你在不破产的情况下部署低延迟大型语言模型?在这篇博文中,我们将重新审视自回归文本生成的瓶颈,并介绍一种新的解码方法来解决延迟问题。你会发现,通过使用我们的新的辅助生成方法,你可以将硬件中的延迟降低多达 10 倍!
理解文本生成延迟
文本生成的核心很容易理解。让我们看看核心部分 (即 ML 模型),它的输入包含一个文本序列,其中包括到目前为止生成的文本,以及其他特定于模型的组件 (例如 Whisper 还有一个音频输入)。该模型接受输入并进行前向传递: 输入被喂入模型并一层一层顺序传递,直到预测出下一个 token 的非标准化对数概率 (也称为 logits)。一个 token 可能包含整个词、子词,或者是单个字符,这取决于具体模型。如果你想深入了解文本生成的原理,GPT-2 插图 是一个很好的参考。
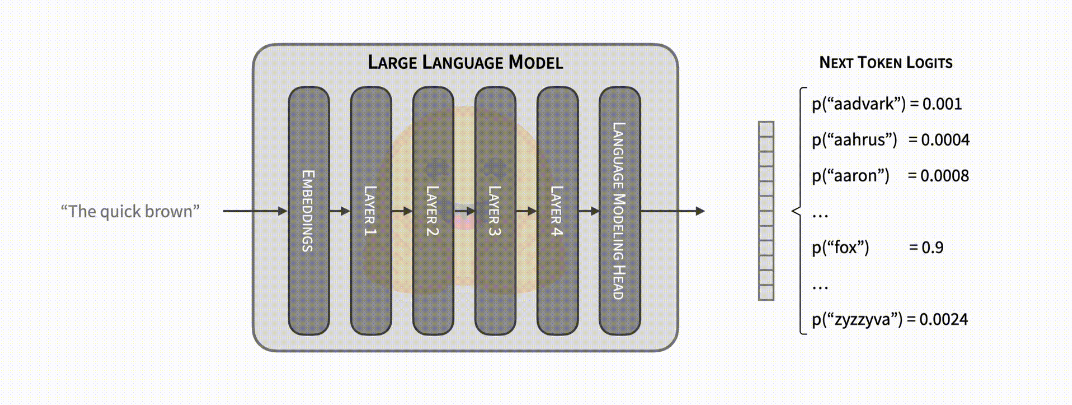
模型的前向传递提供了下一个 token 的概率,你可以自由操作 (例如,将不需要的单词或序列的概率设置为 0)。文本生成的步骤就是从这些概率中选择下一个 token。常见的策略包括选择最有可能的 token (贪心解码),或从它们的分布中抽样 (多项式抽样)。在选择了下一个 token 之后,我们将模型前向传递与下一个 token 迭代地连接起来,继续生成文本。这个解释只是解码方法的冰山一角; 请参阅我们 关于文本生成的博客 以进行深入探索。
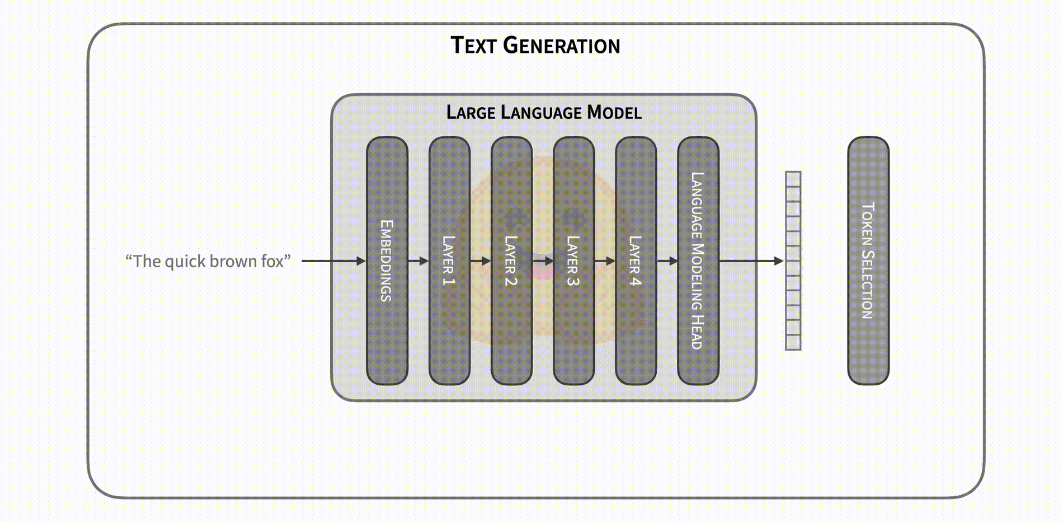
从上面的描述中可以看出,文本生成的延迟瓶颈很明显: 运行大型模型的前向传递很慢,你可能需要依次执行数百次迭代。但让我们深入探讨一下: 为什么前向传递速度慢?前向传递通常以矩阵乘法为主,通过查阅相应的 维基百科,你可以看出内存带宽是此操作的限制 (例如,从 GPU RAM 到 GPU 计算核心)。换句话说, 前向传递的瓶颈来自将模型权重加载到设备的计算核心中,而不是来自执行计算本身。
目前,你可以探索三个主要途径来充分理解文本生成,所有这些途径都用于解决模型前向传递的性能问题。首先,对于特定硬件的模型优化。例如,如果你的设备可能与 Flash Attention 兼容,你可以使用它通可以过重新排序操作或 INT8 量化 来加速注意力层,其减少了模型权重的大小。
其次,如果你有并发文本生成需求,你可以对输入进行批处理,从而实现较小的延迟损失并大幅增加吞吐量。你可以将模型对于多个输入并行计算,这意味着你将在大致相同的内存带宽负担情况下获得了更多 token。批处理的问题在于你需要额外的设备内存 (或在某处卸载内存)。你可以看到像 FlexGen 这样的项目以延迟为代价来优化吞吐量。
# Example showcasing the impact of batched generation. Measurement device: RTX3090
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
model = AutoModelForCausalLM.from_pretrained("distilgpt2").to("cuda")
inputs = tokenizer(["Hello world"], return_tensors="pt").to("cuda")
def print_tokens_per_second(batch_size):
new_tokens = 100
cumulative_time = 0
# warmup
model.generate(
**inputs, do_sample=True, max_new_tokens=new_tokens, num_return_sequences=batch_size
)
for _ in range(10):
start = time.time()
model.generate(
**inputs, do_sample=True, max_new_tokens=new_tokens, num_return_sequences=batch_size
)
cumulative_time += time.time() - start
print(f"Tokens per second: {new_tokens * batch_size * 10 / cumulative_time:.1f}")
print_tokens_per_second(1) # Tokens per second: 418.3
print_tokens_per_second(64) # Tokens per second: 16266.2 (~39x more tokens per second)
最后,如果你有多个可用设备,你可以使用 Tensor 并行 分配工作负载并获得更低的延迟。使用 Tensor 并行,你可以将内存带宽负担分摊到多个设备上,但除了在多个设备运行计算的成本之外,你还需要考虑设备间的通信瓶颈。该方法的收益在很大程度上取决于模型大小: 对于可以轻松在单个消费级设备上运行的模型,通常效果并不显著。根据这篇 DeepSpeed 博客,你会发现你可以将大小为 17B 的模型分布在 4 个 GPU 上,从而将延迟减少 1.5 倍 (图 7)。
这三种类型的改进可以串联使用,从而产生 高通量解决方案。然而,在应用特定于硬件的优化后,降低延迟的方法有限——并且现有的方法很昂贵。让我们接下来解决这个问题!
重新回顾语言模型解码器的正向传播
上文我们讲到,每个模型前向传递都会产生下一个 token 的概率,但这实际上是一个不完整的描述。在文本生成期间,典型的迭代包括模型接收最新生成的 token 作为输入,加上所有其他先前输入的缓存内部计算,再返回下一个 token 得概率。缓存用于避免冗余计算,从而实现更快的前向传递,但它不是强制性的 (并且可以设置部分使用)。禁用缓存时,输入包含到目前为止生成的整个 token 序列,输出包含 _所有位置_的下一个 token 对应的概率分布!如果输入由前 N 个 token 组成,则第 N 个位置的输出对应于其下一个 token 的概率分布,并且该概率分布忽略了序列中的所有后续 token。在贪心解码的特殊情况下,如果你将生成的序列作为输入传递并将 argmax 运算符应用于生成的概率,你将获得生成的序列。
from transformers import AutoModelForCausalLM, AutoTokenizer
tok = AutoTokenizer.from_pretrained("distilgpt2")
model = AutoModelForCausalLM.from_pretrained("distilgpt2")
inputs = tok(["The"], return_tensors="pt")
generated = model.generate(**inputs, do_sample=False, max_new_tokens=10)
forward_confirmation = model(generated).logits.argmax(-1)
# We exclude the opposing tips from each sequence: the forward pass returns
# the logits for the next token, so it is shifted by one position.
print(generated[:-1].tolist() == forward_confirmation[1:].tolist()) # True
这意味着你可以将模型前向传递用于不同的目的: 除了提供一些 token 来预测下一个标记外,你还可以将序列传递给模型并检查模型是否会生成相同的序列 (或部分相同序列)。
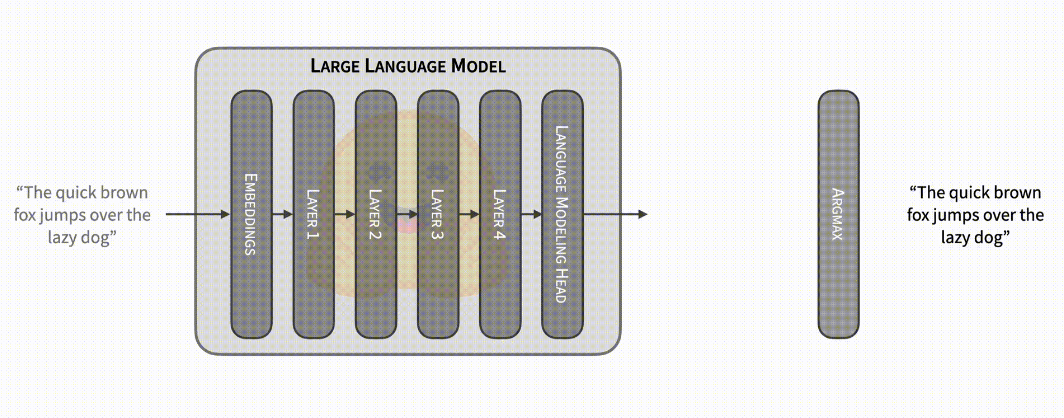
(请访问阅读原文查看动态演示)
让我们想象,你可以访问一个神奇的无延迟的预测辅助模型,该模型针对任何给定输入生成与你的模型相同的序列。顺便说一句,这个模型不能直接用,只能辅助你的生成程序。使用上述属性,你可以使用此辅助模型获取候选输出 token,然后使用你的模型进行前向传递以确认它们的正确性。在这个乌托邦式的场景中,文本生成的延迟将从 O(n) 减少到 O(1),其中生成的 token 数量为 n。对于需要多次迭代生成的过程,我们谈论的是其数量级。
向现实迈出一步,我们假设辅助模型失去了它的预测属性。根据你的模型,现在它是一个无延迟模型,但它会弄错一些候选 token。由于任务的自回归性质,一旦辅助模型得到一个错误的 token,所有后续候选 token 都必须无效。但是,你可以使用模型更正错误 token 并反复重复此过程后再次查询辅助模型。即使辅助模型失败了几个 token,文本生成的延迟也会比原始形式小得多。
显然,世界上没有无延迟的辅助模型。然而,找到一个近似于模型的文本生成输出的其它模型相对容易,例如经过类似训练的相同架构的较小版本模型通常符合此需求。当模型大小的差异变得显著时,使用较小的模型作为辅助模型的成本在跳过几个前向传递后就显得无关紧要了!现在,你了解了 _ 辅助生成 _ 的核心。
使用辅助模型的贪心解码
辅助生成是一种平衡行为。你希望辅助模型快速生成候选序列,同时尽可能准确。如果辅助模型的质量很差,你将承担使用辅助模型的成本,而收益却很少甚至没有。另一方面,优化候选序列的质量可能意味着使用更慢的辅助模型,从而导致网络减速。虽然我们无法为你自动选择辅助模型,但我们包含了一个额外的要求和一个启发式方法,以确保模型与辅助模型一起花费的时间保持在可控范围内。
首先,我们要求辅助模型必须具有与你的模型完全相同的分词器。如果没有此要求,则必须添加昂贵的 token 解码和重新编码步骤。此外,这些额外的步骤必须在 CPU 上进行,这反过来可能增加了设备间数据传输。能够快速地使用辅助模型对于辅助生成的好处是至关重要的。
最后,启发式。至此,你可能已经注意到电影盗梦空间和辅助生成之间的相似之处——毕竟你是在文本生成中运行文本生成。每个候选 token 有一个辅助模型前向传播,我们知道前向传播是昂贵的。虽然你无法提前知道辅助模型将获得的 token 数量,但你可以跟踪此信息并使用它来限制向辅助模型请求的候选 token 数量——输出的某些部分比其它一些部分更容易被预计。
总结一下,这是我们最初实现的辅助生成的循环 (代码):
- 使用贪心解码与辅助模型生成一定数量的
候选 token。当第一次调用辅助生成时,生成的候选 token的数量被初始化为5。 - 使用我们的模型,对
候选 token进行前向计算,获得每个 token 对应的概率。 - 使用 token 选择方法 (使用
.argmax()进行贪心搜索或使用.multinomial()用于采样方法) 来从概率中选取next_tokens。 - 比较步骤 3 中选择的
next_tokens和候选 token中相同的 token 数量。请注意,我们需要从左到右进行比较, 在第一次不匹配后,后续所有候选 token都无效。5. 使用步骤 4 得到的匹配数量将候选 token分割。也就是,将输入 tokens 加上刚刚验证得到的正确的 tokens。 - 调整下一次迭代中生成的
候选 token的数量 —— 使用启发式方法,如果步骤 3 中所有 token 都匹配,则候选 token的长度增加2,否则减少1。
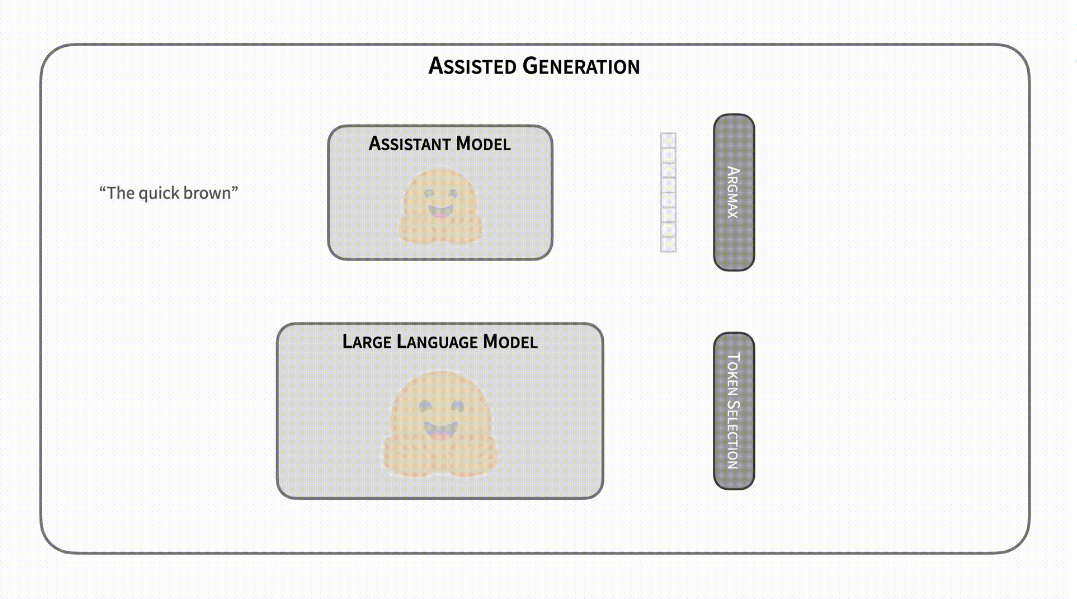
(请访问阅读原文查看动态演示)
我们在 ![]() Transformers 中设计了 API,因此使用该方法对你来说是无痛的。你需要做的就是将辅助模型作为
Transformers 中设计了 API,因此使用该方法对你来说是无痛的。你需要做的就是将辅助模型作为 assistant_model 参数传入从而获得延迟收益!我们暂时限制了辅助生成的批量大小为 1。
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
prompt = "Alice and Bob"
checkpoint = "EleutherAI/pythia-1.4b-deduped"
assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt").to(device)
model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device)
assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint).to(device)
outputs = model.generate(**inputs, assistant_model=assistant_model)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
# ['Alice and Bob are sitting in a bar. Alice is drinking a beer and Bob is drinking a']
额外的内部复杂性是否值得?让我们看一下贪心解码情况下的延迟数 (采样结果在下一节)。考虑批量大小为 1,这些结果是直接从 ![]() Transformers 中提取的,没有任何额外的优化,因此你应该能够在你的设置中复现它们。
Transformers 中提取的,没有任何额外的优化,因此你应该能够在你的设置中复现它们。
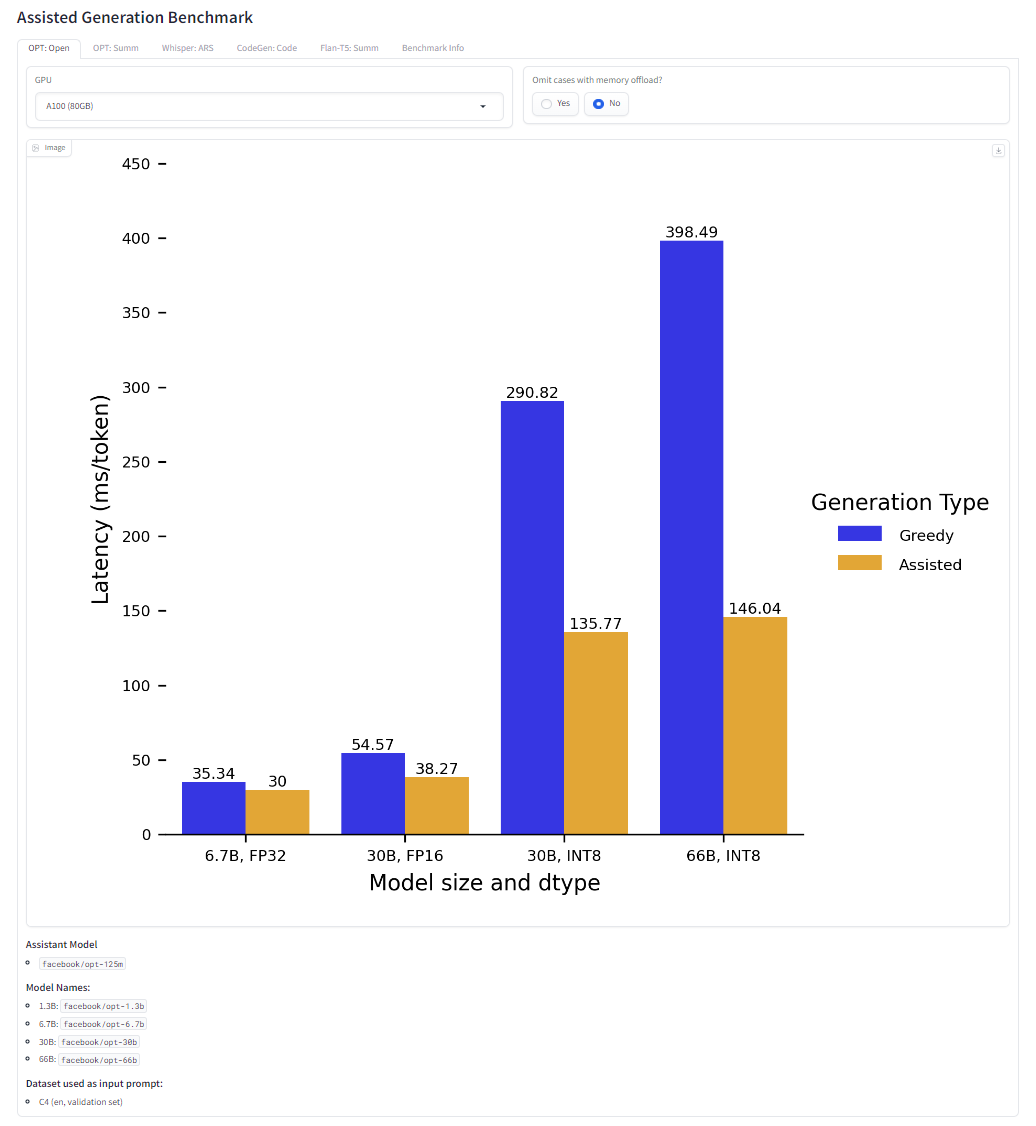
Space 体验地址: https://hf.co/spaces/joaogante/assisted_generation_benchmarks
通过观察收集到的数据,我们发现辅助生成可以在不同的设置中显著减少延迟,但这不是灵丹妙药——你应该在应用之前对其进行系统的评估以清晰使用该方法的代价。对于辅助生成方法,我们可以得出结论:
 需要访问至少比你的模型小一个数量级的辅助模型 (差异越大越好) ;
需要访问至少比你的模型小一个数量级的辅助模型 (差异越大越好) ; 在存在 INT8 的情况下获得高达 3 倍的加速,否则能够达到 2 倍的加速;
在存在 INT8 的情况下获得高达 3 倍的加速,否则能够达到 2 倍的加速; 如果你正在使用不适合你的模型的 GPU 并且依赖于内存卸载的模型,你可以看到高达 10 倍的加速;
如果你正在使用不适合你的模型的 GPU 并且依赖于内存卸载的模型,你可以看到高达 10 倍的加速; 在输入驱动任务中大放异彩,例如自动语音识别或摘要。
在输入驱动任务中大放异彩,例如自动语音识别或摘要。
辅助生成的采样方法
贪心解码适用于以输入为基础的任务 (自动语音识别、翻译、摘要……) 或事实知识寻求。对于需要大量创造力的开放式任务,例如使用语言模型作为聊天机器人的大多数任务,应该改用采样方法。虽然辅助生成方法是为贪心解码而设计的,但这并不意味着你不能使用多项式采样进行辅助生成!
从 next token 的概率分布中抽取样本将导致我们的基于贪心的辅助生产更频繁地失败,从而降低其延迟优势。但是,我们可以使用采样中的温度系数来控制下一个标记的概率分布有多尖锐。在一种极端情况下,当温度接近 0 时,采样将近似于贪心解码,有利于最有可能的 token。在另一个极端,当温度设置为远大于 1 的值时,采样将是混乱的,从均匀分布中抽取。因此,低温对你的辅助模型更有利,能够保留辅助生成的大部分延迟优势,如下所示。
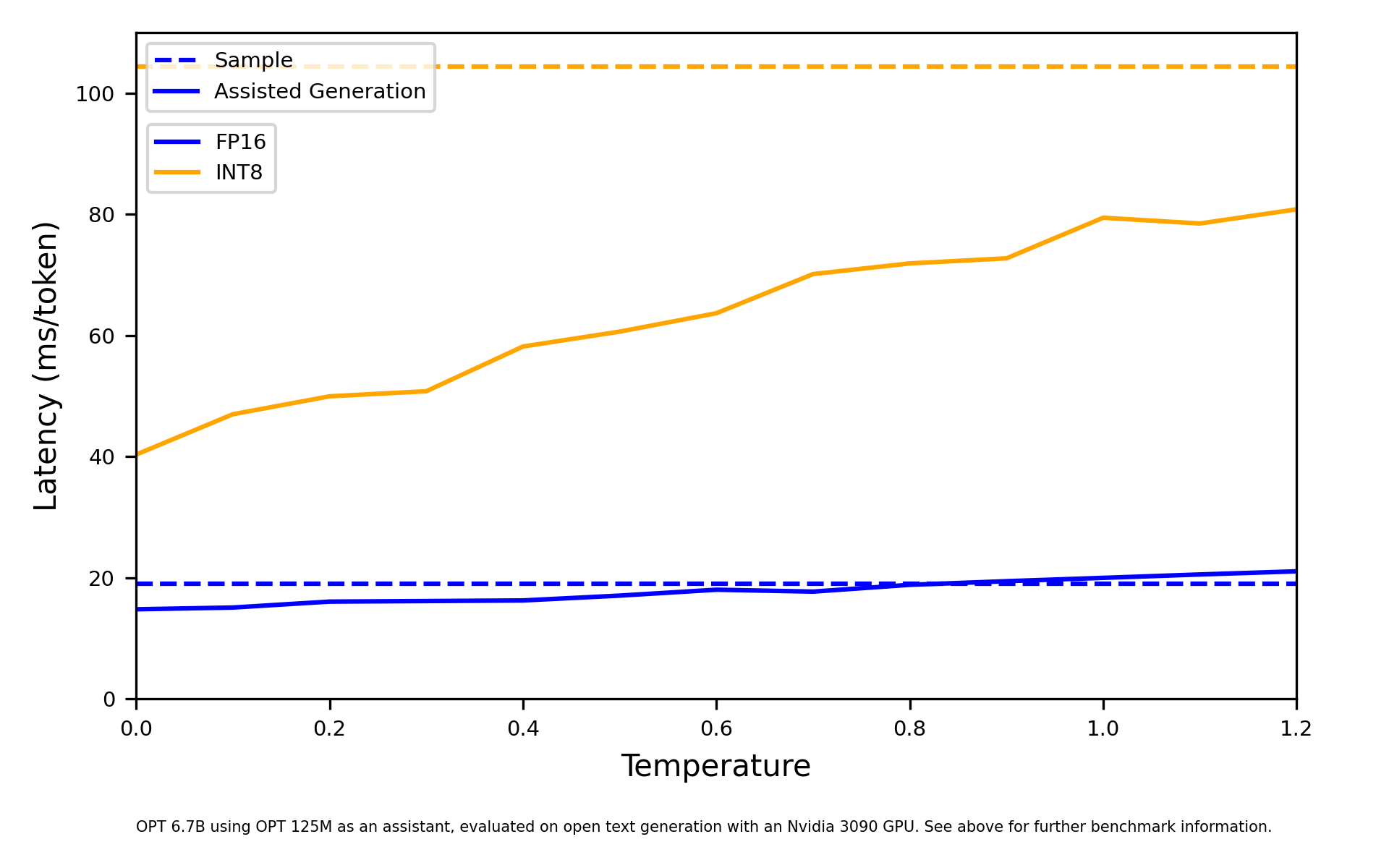
不妨亲眼看一看,感受一下辅助生成的魅力?
Space 体验地址: https://hf.co/spaces/joaogante/assisted_generation_demo
未来发展方向
辅助生成表明当前文本生成策略已经到了可优化的阶段。我们意识到它目前的难点不在于计算量的问题,因此可以应用简单的启发式方法来充分利用可用的内存带宽,缓解瓶颈。我们相信,进一步优化辅助模型将使我们获得更大的延迟降低——例如,如果我们请求辅助模型生成多个连续候选 token,我们可能能够跳过更多的前向传递。自然地,使用高质量的小模型作为辅助模型对于实现和扩大收益至关重要。
该方法最初在我们的 ![]() Transformers 库下发布,用于
Transformers 库下发布,用于 .generate() 函数,我们预期将其纳入整个 Hugging Face 宇宙。它的实现也是完全开源的。因此,如果你正在进行文本生成而没有使用我们的工具,你可以随时将其作为参考。
最后,辅助生成重新提出了文本生成中的一个关键问题: 模型中所有新 token 都是给定模型以自回归方式计算的结果,同质地前向传递每一个 token。这篇博文提出了这样的想法: 生成的大部分序列也可以由小尺寸的模型同样生成。为此,我们需要新的模型架构和解码方法——我们很高兴看到未来会带来什么!
相关工作
在这篇博文最初发布后,我注意到其他作品也探索了相同的核心原则 (使用前向传递来验证更长的连续性)。特别地,请看以下作品:
Citation
@misc {gante2023assisted,
author = { {Joao Gante} },
title = { Assisted Generation: a new direction toward low-latency text generation },
year = 2023,
url = { https://huggingface.co/blog/assisted-generation },
doi = { 10.57967/hf/0638 },
publisher = { Hugging Face Blog }
}
致谢
我要感谢 Sylvain Gugger、Nicolas Patry 和 Lewis Tunstall 分享了许多宝贵的建议来改进这篇博文。最后,感谢 Chunte Lee 设计了精美的封面,你可以在我们的网页上看到。
原文链接: https://huggingface.co/blog/assisted-generation
作者: Joao Gante
译者: gxy-gxy
排版/审校: zhongdongy (阿东)