更快的辅助生成: 动态推测
![]() 在这篇博客文章中,我们将探讨 动态推测解码 ——这是由英特尔实验室和 Hugging Face 开发的一种新方法,可以加速文本生成高达 2.7 倍,具体取决于任务。从 Transformers
在这篇博客文章中,我们将探讨 动态推测解码 ——这是由英特尔实验室和 Hugging Face 开发的一种新方法,可以加速文本生成高达 2.7 倍,具体取决于任务。从 Transformers![]() 发布的版本 4.45.0 开始,这种方法是辅助生成的默认模式
发布的版本 4.45.0 开始,这种方法是辅助生成的默认模式![]()
推测解码
推测解码 技术十分流行,其用于加速大型语言模型的推理过程,与此同时保持其准确性。如下图所示,推测解码通过将生成过程分为两个阶段来工作。在第一阶段,一个快速但准确性较低的 草稿 模型 (Draft,也称为助手) 自回归地生成一系列标记。在第二阶段,一个大型但更准确的 目标 模型 (Target) 对生成的草稿标记进行并行验证。这个过程允许目标模型在单个前向传递中生成多个标记,从而加速自回归解码。推测解码的成功在很大程度上取决于 推测前瞻 (Speculative Lookahead,下文用 SL 表示),即草稿模型在每次迭代中生成的标记数量。在实践中,SL 要么是一个静态值,要么基于启发式方法,这两者都不是在推理过程中发挥最大性能的最优选择。
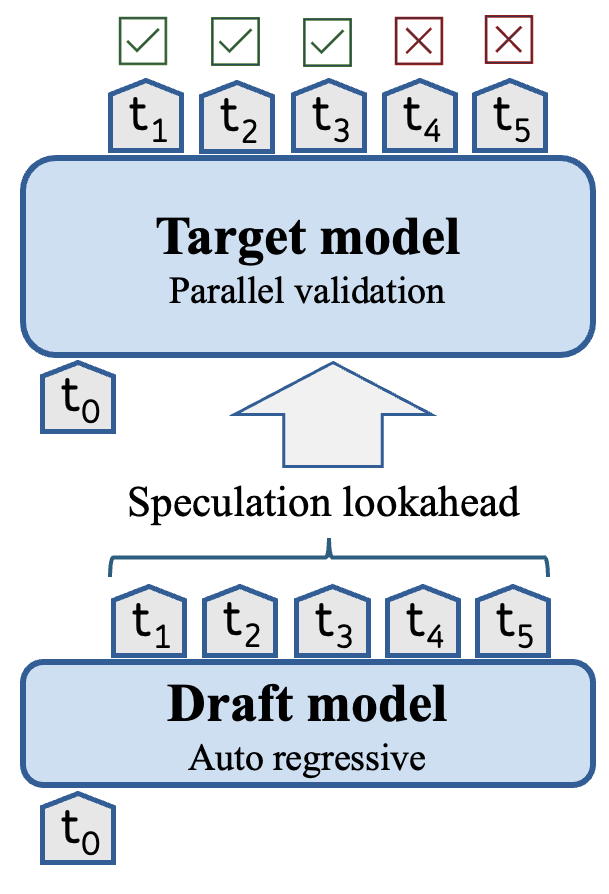
推测解码的单次迭代
动态推测解码
Transformers![]() 库提供了两种不同的方法来确定在推理过程中调整草稿 (助手) 标记数量的计划。基于 Leviathan 等人 的直接方法使用推测前瞻的静态值,并涉及在每个推测迭代中生成恒定数量的候选标记。另一种 基于启发式方法的方法 根据当前迭代的接受率调整下一次迭代的候选标记数量。如果所有推测标记都是正确的,则候选标记的数量增加; 否则,数量减少。
库提供了两种不同的方法来确定在推理过程中调整草稿 (助手) 标记数量的计划。基于 Leviathan 等人 的直接方法使用推测前瞻的静态值,并涉及在每个推测迭代中生成恒定数量的候选标记。另一种 基于启发式方法的方法 根据当前迭代的接受率调整下一次迭代的候选标记数量。如果所有推测标记都是正确的,则候选标记的数量增加; 否则,数量减少。
我们预计,通过增强优化策略来管理生成的草稿标记数量,可以进一步减少延迟。为了测试这个论点,我们利用一个预测器来确定每个推测迭代的最佳推测前瞻值 (SL)。该预测器利用草稿模型自回归的生成标记,直到草稿模型和目标模型之间的预测标记出现不一致。该过程在每个推测迭代中重复进行,最终确定每次迭代接受的草稿标记的最佳 (最大) 数量。草稿/目标标记不匹配是通过在零温度下 Leviathan 等人提出的拒绝抽样算法 (rejection sampling algorithm) 来识别的。该预测器通过在每一步生成最大数量的有效草稿标记,并最小化对草稿和目标模型的调用次数,实现了推测解码的全部潜力。我们称使用该预测器得到 SL 值的推测解码过程为预知 (orcale) 的推测解码。
下面的左图展示了来自 MBPP 数据集的代码生成示例中的预知和静态推测前瞻值在推测迭代中的变化。可以观察到预知的 SL 值 (橙色条) 存在很高的变化。
静态 SL 值 (蓝色条) 中,生成的草稿标记数量固定为 5,执行了 38 次目标前向传播和 192 次草稿前向传播,而预知的 SL 值只执行了 27 次目标前向传播和 129 次草稿前向传播 - 减少了很多。右图展示了整个 Alpaca 数据集中的预知和静态推测前瞻值。
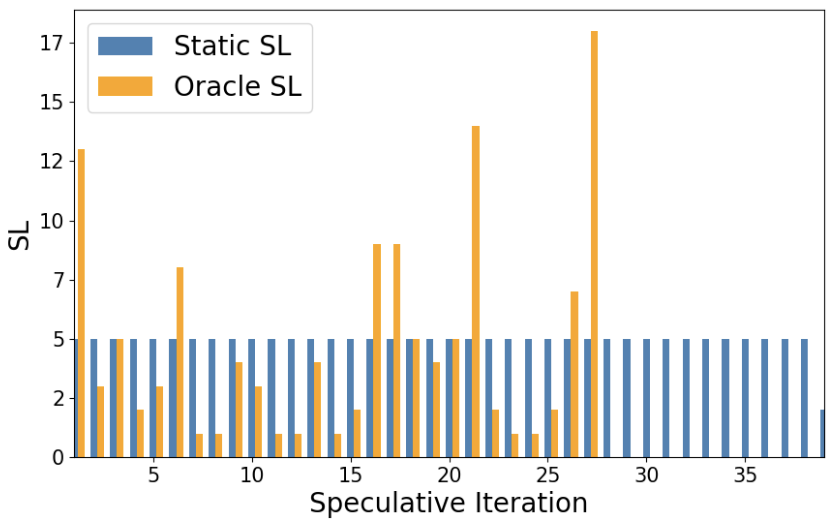
在 MBPP 的一个例子上的预知和静态推测前瞻值 (SL)。
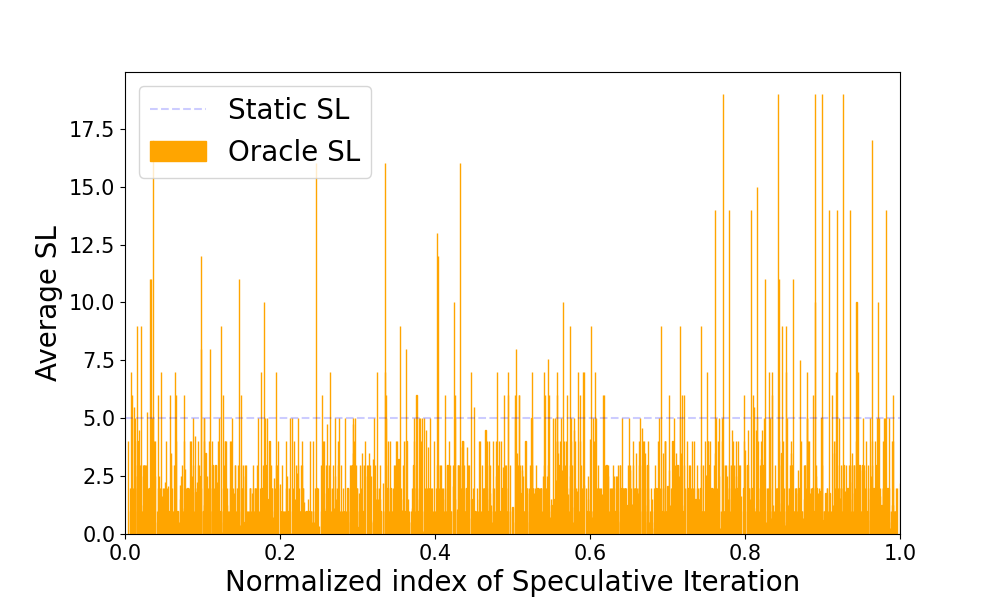
在整个 Alpaca 数据集上平均的预知 SL 值。
上面的两个图表展示了预知推测前瞻值的多变性,这说明静态的推测解码可能使次优的。
为了更接近预知的推测解码并获得额外的加速,我们开发了一种简单的方法来在每次迭代中动态调整推测前瞻值。在生成每个草稿令牌后,我们确定草稿模型是否应继续生成下一个令牌或切换到目标模型进行验证。这个决定基于草稿模型对其预测的信心,通过 logits 的 softmax 估计。如果草稿模型对当前令牌预测的信心低于预定义的阈值,即 assistant_confidence_threshold ,它将在该迭代中停止令牌生成过程,即使尚未达到最大推测令牌数 num_assistant_tokens 。一旦停止,当前迭代中生成的草稿令牌将被发送到目标模型进行验证。
基准测试
我们在一系列任务和模型组合中对动态方法与启发式方法进行了基准测试。动态方法在所有测试中表现出更好的性能。
值得注意的是,使用动态方法将 Llama3.2-1B 作为 Llama3.1-8B 的助手时,我们观察到速度提升高达 1.52 倍,而使用相同设置的启发式方法则没有显著的速度提升。另一个观察结果是, codegen-6B-mono 在使用启发式方法时表现出速度下降,而使用动态方法则表现出速度提升。
| 目标模型 | 草稿模型 | 任务类型 | 加速比 - 启发式策略 | 加速比 - 动态策略 |
|---|---|---|---|---|
facebook/opt-6.7b |
facebook/opt-125m |
summarization | 1.82x | 2.71x |
facebook/opt-6.7b |
facebook/opt-125m |
open-ended generation | 1.23x | 1.59x |
Salesforce/codegen-6B-mono |
Salesforce/codegen-350M-mono |
code generation (python) | 0.89x | 1.09x |
google/flan-t5-xl |
google/flan-t5-small |
summarization | 1.18x | 1.31x |
meta-llama/Llama-3.1-8B |
meta-llama/Llama-3.2-1B |
summarization | 1.00x | 1.52x |
meta-llama/Llama-3.1-8B |
meta-llama/Llama-3.2-1B |
open-ended generation | 1.00x | 1.18x |
meta-llama/Llama-3.1-8B |
meta-llama/Llama-3.2-1B |
code generation (python) | 1.09x | 1.15x |
- 表格中的结果反映了贪婪解码 (temperature = 0)。在使用采样 (temperature > 0) 时也观察到了类似的趋势。
- 所有测试均在 RTX 4090 上进行。
- 我们的基准测试是公开的,允许任何人评估进一步的改进: huggingface-demos/experiments/faster_generation at main · gante/huggingface-demos · GitHub
代码
动态推测已经整合到 Hugging Face Transformers 库的 4.45.0 版本中,并且现在作为辅助解码的默认操作模式。要使用带有动态推测的辅助生成,无需进行任何代码更改,只需像平常一样执行代码即可:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
prompt = "Alice and Bob"
checkpoint = "EleutherAI/pythia-1.4b-deduped"
assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt").to(device)
model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device)
assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint).to(device)
outputs = model.generate(**inputs, assistant_model=assistant_model)
默认的动态推测前瞻的参数反应了最优的值,但是可以使用下面的代码进行调整来在特定模型和数据上获得更好的性能:
# confidence threshold
assistant_model.generation_config.assistant_confidence_threshold=0.4
# 'constant' means that num_assistant_tokens stays unchanged during generation
assistant_model.generation_config.num_assistant_tokens_schedule='constant'
# the maximum number of tokens generated by the assistant model.
# after 20 tokens the draft halts even if the confidence is above the threshold
assistant_model.generation_config.num_assistant_tokens=20
要恢复到 启发式 或 静态 方法 (如 Leviathan 等人 中所述),只需分别将 num_assistant_tokens_schedule 设置为 'heuristic' 或 'constant' ,将 assistant_confidence_threshold=0 和 num_assistant_tokens=5 设置如下:
# Use 'heuristic' or 'constant' or 'dynamic'
assistant_model.generation_config.num_assistant_tokens_schedule='heuristic'
assistant_model.generation_config.assistant_confidence_threshold=0
assistant_model.generation_config.num_assistant_tokens=5
接下来是什么?
我们介绍了一种更快的辅助生成策略,名为动态推测解码,它优于启发式方法以及固定数量候选标记的方法。
在即将发布的博客文章中,我们将展示一种新的辅助生成方法: 将任何目标模型与任何助手模型结合起来!这将为在 Hugging Face Hub 上加速无法获得足够小的助手变体的无数模型打开大门。例如, Phi 3 、 Gemma 2 、 CodeLlama 等等都将有资格进行推测解码。敬请关注!
参考资料
在这篇论文中,我们介绍了 DISCO,一种动态推测前瞻优化方法,利用分类器决定草稿模型是否应该继续生成下一个标记,还是暂停,并切换到目标模型进行验证,而不是仅仅使用对预测概率的简单阈值。
- Assisted Generation: a new direction toward low-latency text generation
- Fast Inference from Transformers via Speculative Decoding
原文链接: https://hf.co/blog/dynamic_speculation_lookahead
原文作者: Jonathan Mamou, Oren Pereg, Joao Gante, Lewis Tunstall, Daniel Korat, Nadav Timor, Moshe Wasserblat
译者: Zipxuan