
正式向大家介绍 TRL——Transformer Reinforcement Learning。这是一个超全面的全栈库,包含了一整套工具用于使用强化学习 (Reinforcement Learning) 训练 transformer 语言模型。从监督调优 (Supervised Fine-tuning step, SFT),到训练奖励模型 (Reward Modeling),再到近端策略优化 (Proximal Policy Optimization),实现了全面覆盖!并且 TRL 库已经与 ![]() transformers 集成,方便你直接使用!
transformers 集成,方便你直接使用!
![]() 文档地址在这里 https://hf.co/docs/trl/
文档地址在这里 https://hf.co/docs/trl/
小编带大家简单看看 API 文档里各个部分对应了什么需求:
-
Model Class: 涵盖了每个公开模型各自用途的概述
-
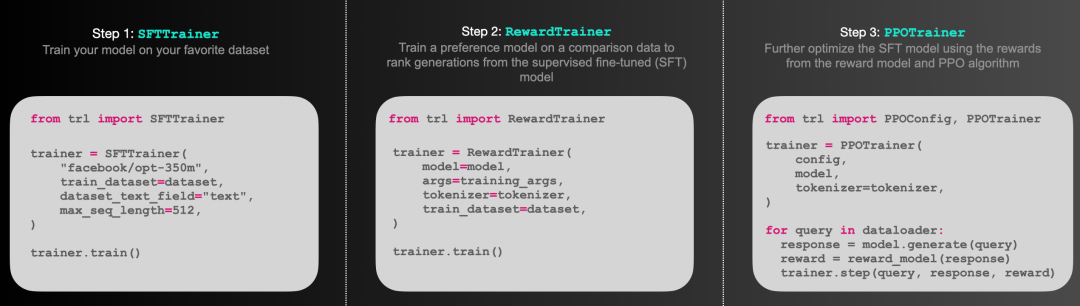
SFTTrainer: 帮助你使用 SFTTrainer 实现模型监督调优
-
RewardTrainer: 帮助你使用 RewardTrainer 训练奖励模型
-
PPOTrainer: 使用 PPO 算法进一步对经过监督调优的模型再调优
-
Best-of-N Samppling: 将“拔萃法”作为从模型的预测中采样的替代方法
-
DPOTrainer: 帮助你使用 DPOTrainer 完成直接偏好优化
文档中还给出了几个例子供 ![]() 宝子们参考:
宝子们参考:
-
Sentiment Tuning: 调优模型以生成更积极的电影内容
-
Training with PEFT: 执行由 PEFT 适配器优化内存效率的 RLHF 训练
-
Detoxifying LLMs: 通过 RLHF 为模型解毒,使其更符合人类的价值观
-
StackLlama: 在 Stack exchange 数据集上实现端到端 RLHF 训练一个 Llama 模型
-
Multi-Adapter Training: 使用单一模型和多适配器实现优化内存效率的端到端训练
![]() 宝子们快行动起来,训练你的第一个 RLHF 模型吧!https://github.com/huggingface/trl
宝子们快行动起来,训练你的第一个 RLHF 模型吧!https://github.com/huggingface/trl